Devlog
June 12 2026 - Starting honours thesis
Goal: Create honours thesis repo and start testing reBot arm in simulation
Work Done:
- Created thesis repo using Boyuan Chen's research template repo
- read about the structure of the template
- vendored the rebot arm urdf from https://github.com/EclipseaHime017/reBotArmController_ROS2/tree/main
- implemented basic mujoco scene with arm and ik
- also ordered reBot arm and ZED Mini camera a few days ago (RIP my wallet TT)
Successes:
-
Failures:
- N/A
Next steps:
- Finish 3d vision and philosphy courses at ETH
- Continue brainstorming thesis topic ideas / experiments
- Build the actual arm
- Design the arm + camera mount and order t slots, nuts, and bolts
Time spent: 2 hours
April 12 - 17 - single task training and testing LeWAM v0.3
Goal: Train a single task pick and place policy using LeWAM
Work Done:
- significantly improved dataloading speed by preprocessing before training
- av1 -> h264 encoding, long -> short gop length
- pre crop from 640 x 480 -> 256x256
- improved time per batch 8sec -> 0.05 sec
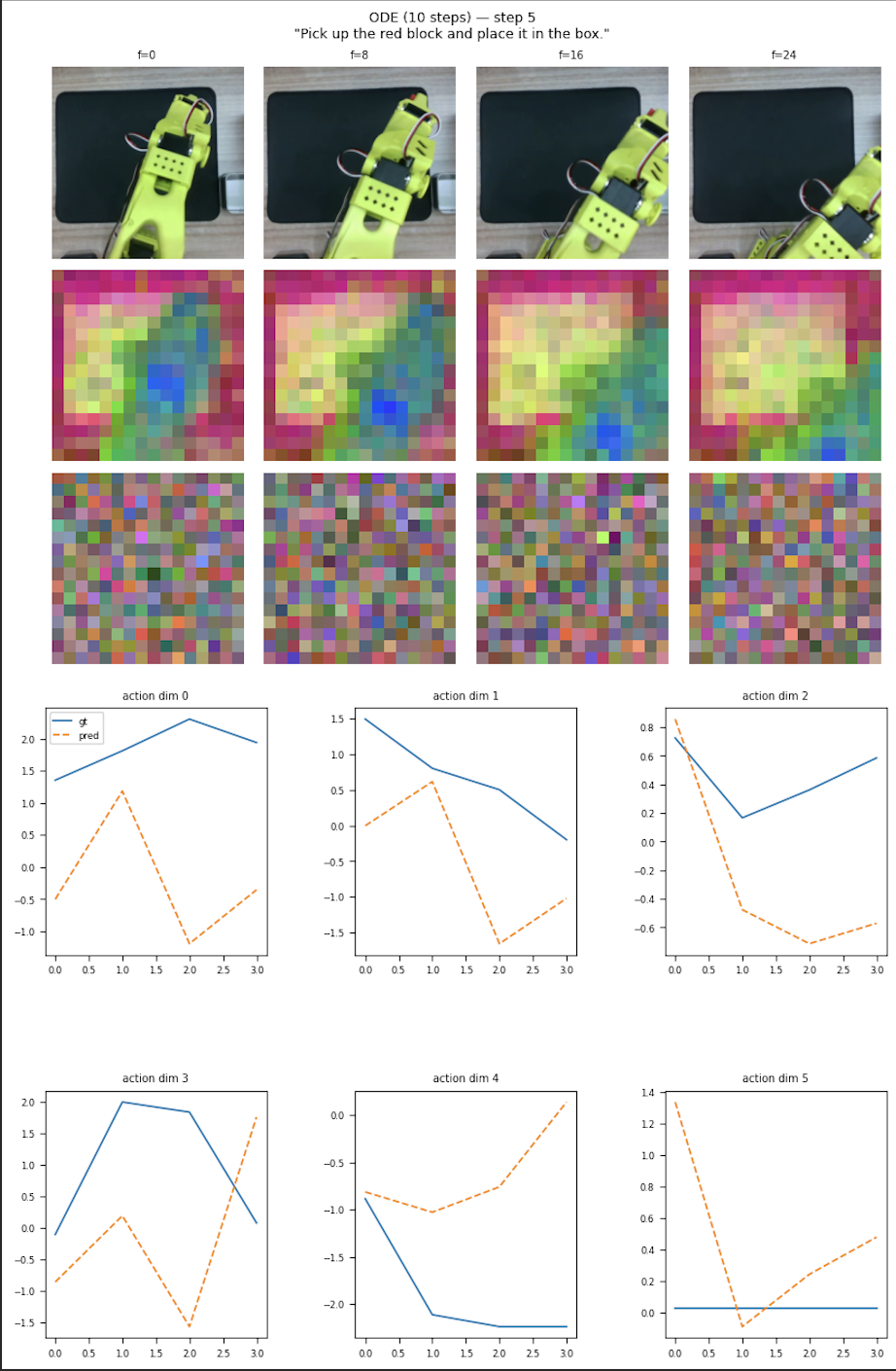
- trained LeWAM v0.3 single task policies, with and without video pretraining (single task pretraining)
Successes:
- Training is much faster despite using a much larger model, ~16k steps per 24 hours @ batch size 40
- gradient checkpointing + video preprocessing helps a lot
- video-only pretraining significantly improves video prediction quality at the same step count
- action-video gradient alignement is also better after training video only first
- policy is able to sometimes grasp the cube, with 1/20 chance it fully completes the task
Failures:
- policy is still unable to consistently complete the full pick and place task 19/20 times
- Mainly grasping issues. Potentially mismatch between the teleoperation commands and the recorded join state
- when teleoperating, need to squeeze gripper more than the actual gripper goes in order to apply force.
Next steps:
- video only pre train on full community dataset
- collect data on an easier task? rubiks cube is not easy to pick up with so101 standard gripper
- fine tune smolvla on the same data to see if its a data problem
Time spent: 10 hours
March 27 - April 10 - LeWAM scaling + arch updates + experiments
Goal: Develop, test, and iterate LeWAM architecture and data pipeline
Work Done:
- create v0.1 and 0.2 arch
- tested both architectures with pretraining, overfitting, policy rollouts, etc.
- set up cloud training infra with vast.ai
- started writing up the paper
- read a ton of WAM and VLA papers for reference
- tested in real life on so101 arm
Successes:
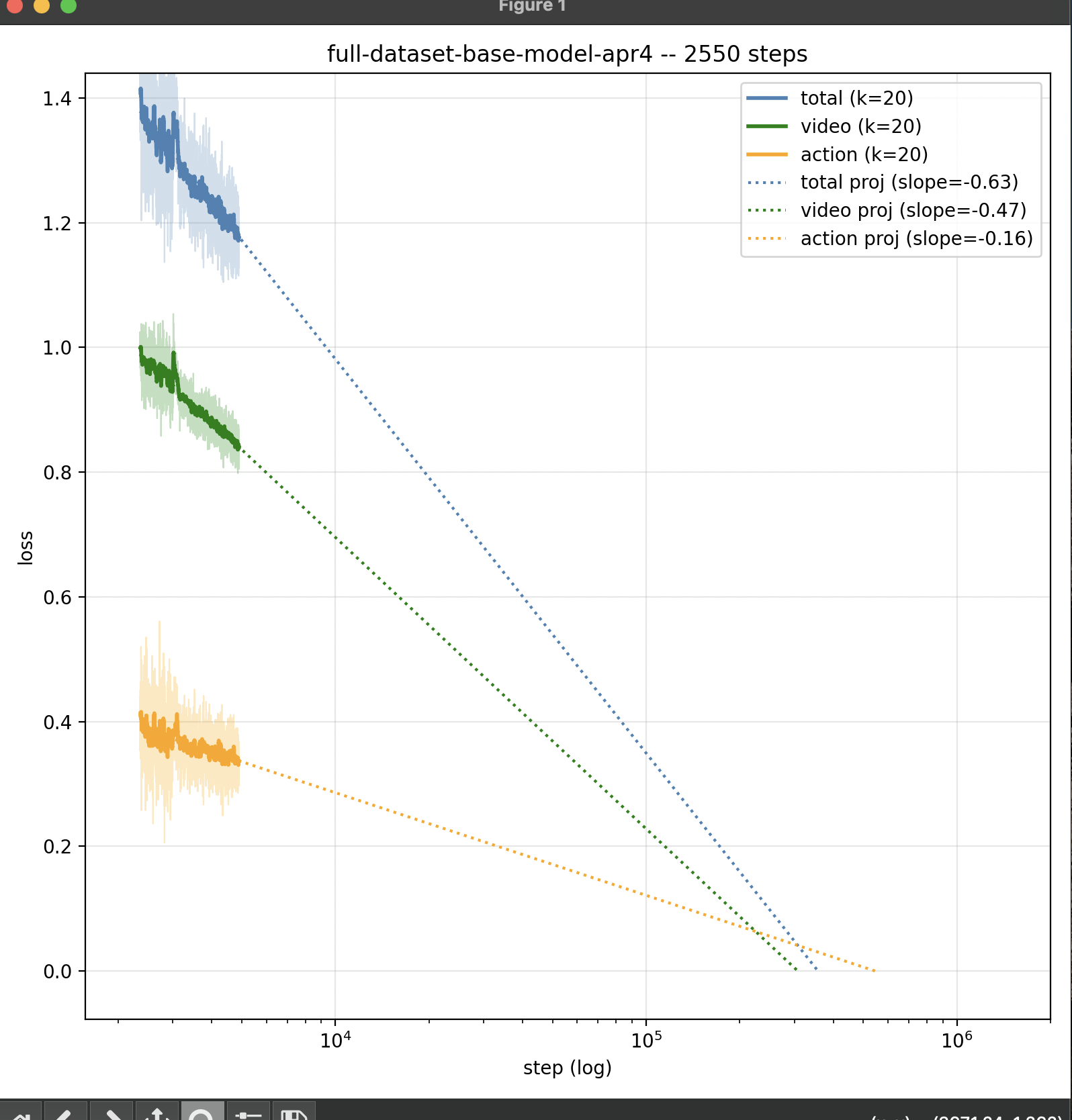
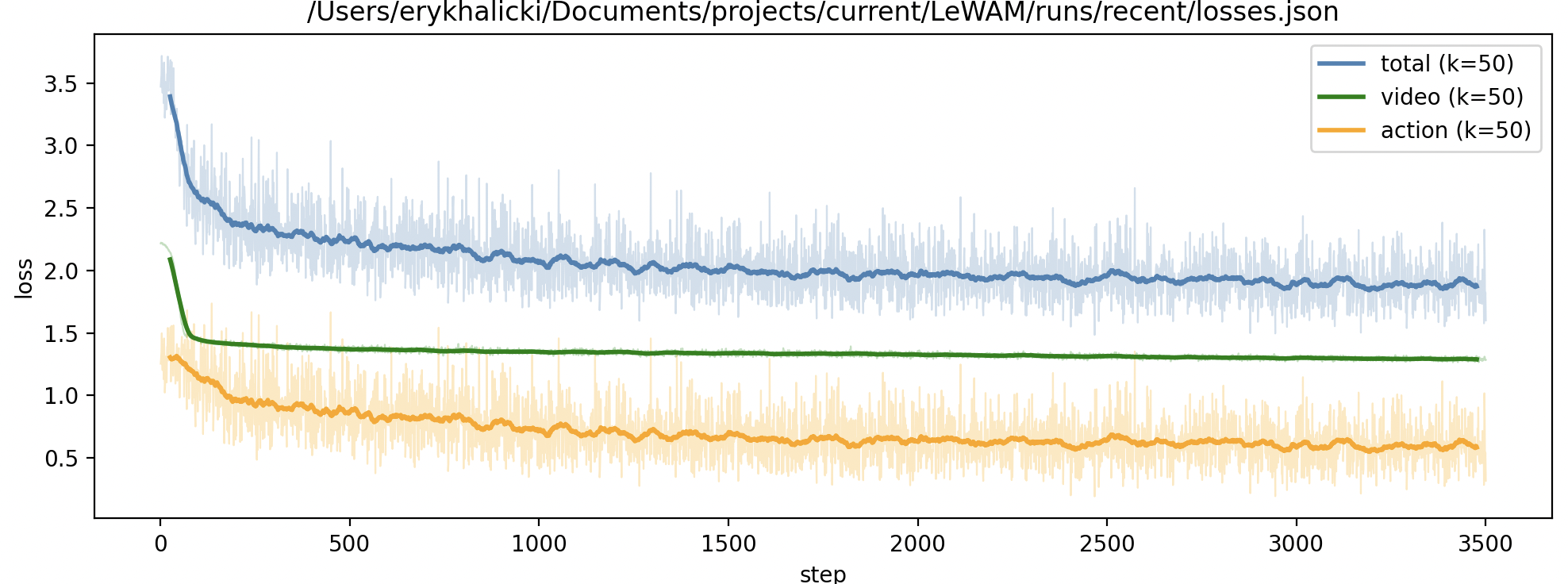
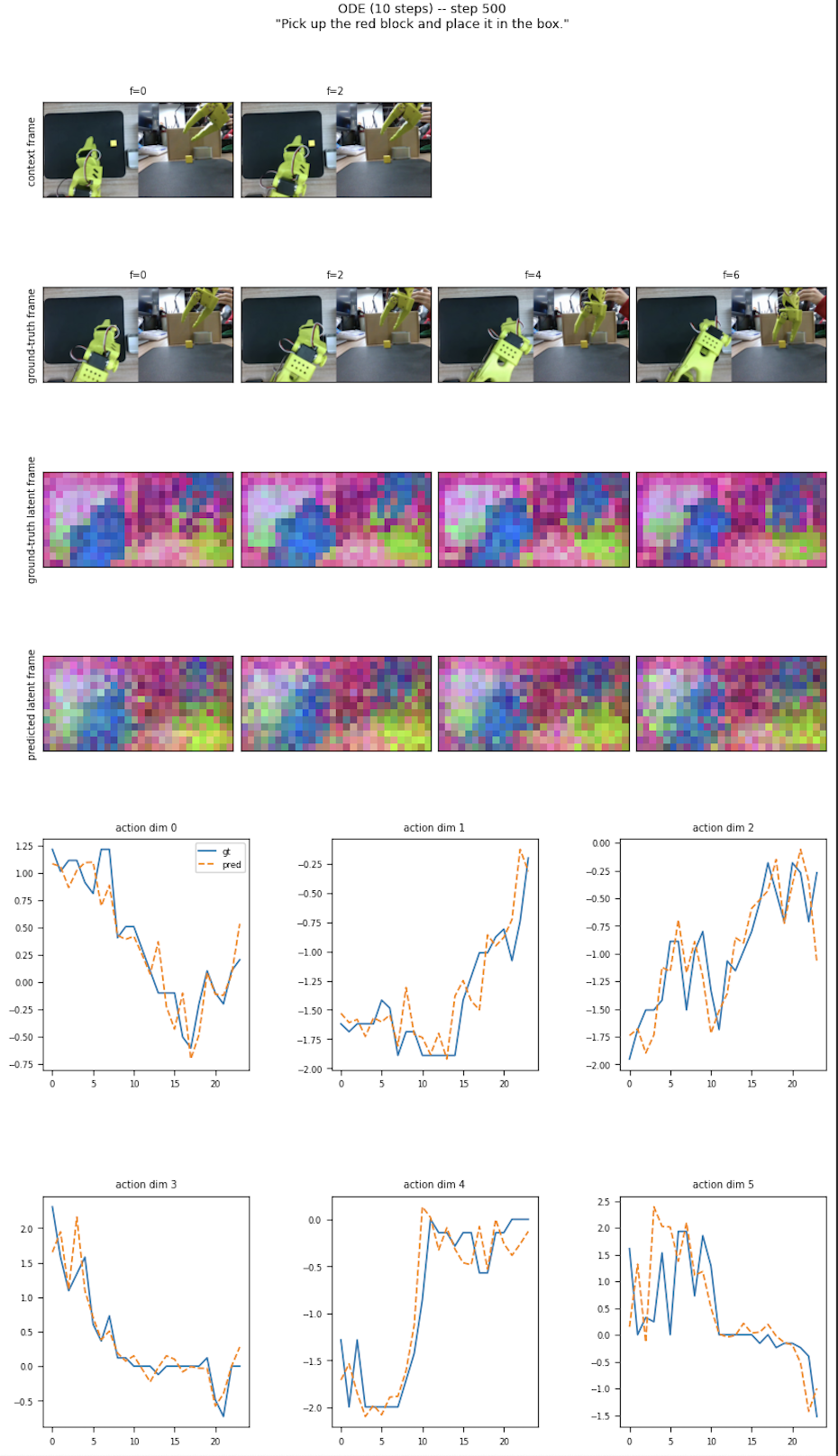
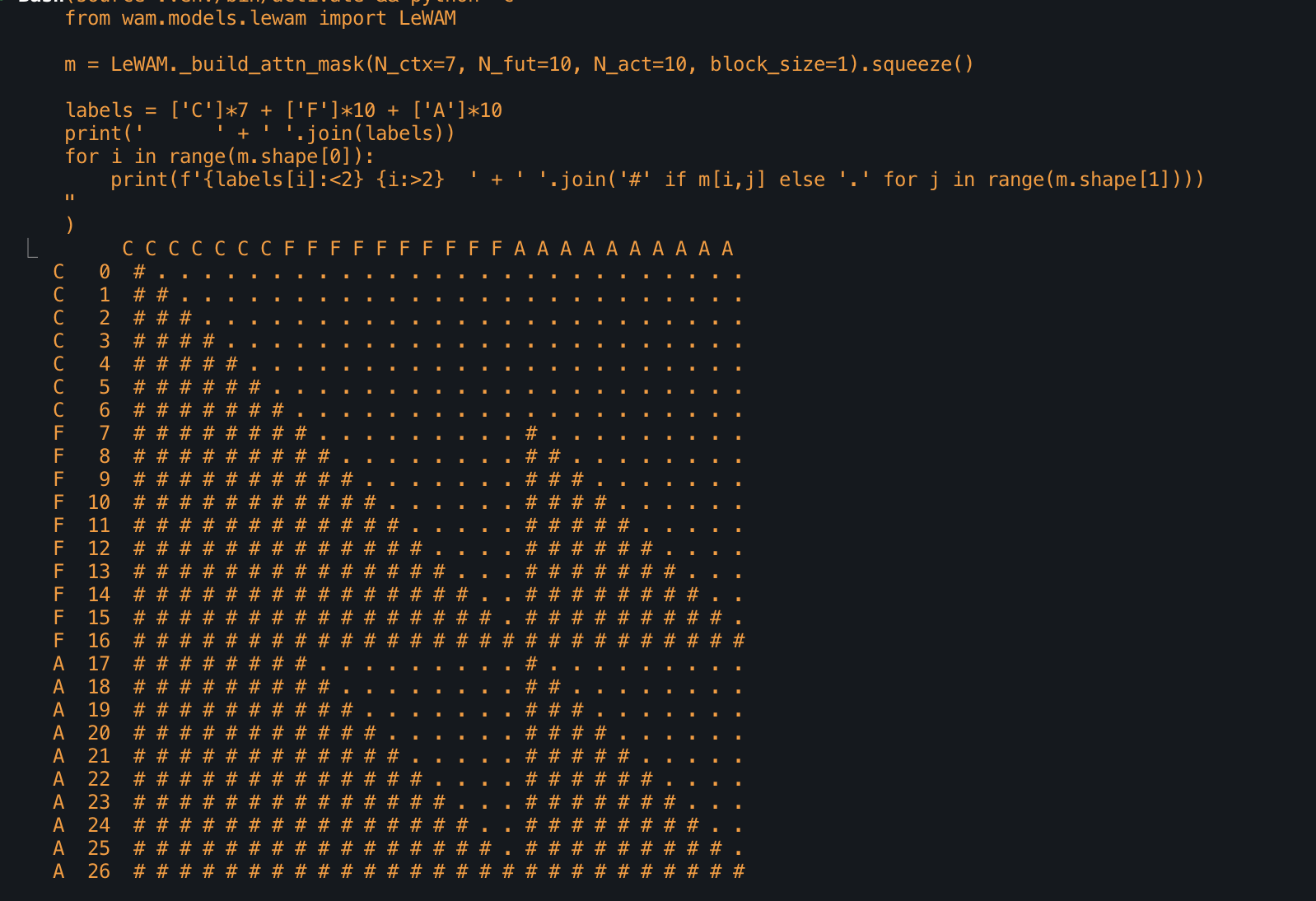
Failures:
- v0.1 was not able to overfit a single frame (forgot to add positional embeddings, plus IDM design was clunky)
- v0.2 was not able to learn simple pick and place task after thousands of steps at large batch size
- burned 200$ on vast.ai :(
Next steps:
- pivoting to new architecture and more ground up approach
- studying for ETH exams so i can resume the project ASAP
Time spent: 100+ hours
March 26 - LeWorldActionModel
Goal: Plan and start working on a World Action Model experiment
Work Done:
- Planned architecture, backbones, and datasets
- Read LeWorldModel, V-JEPA2
- Learned about flow matching and diffusion models
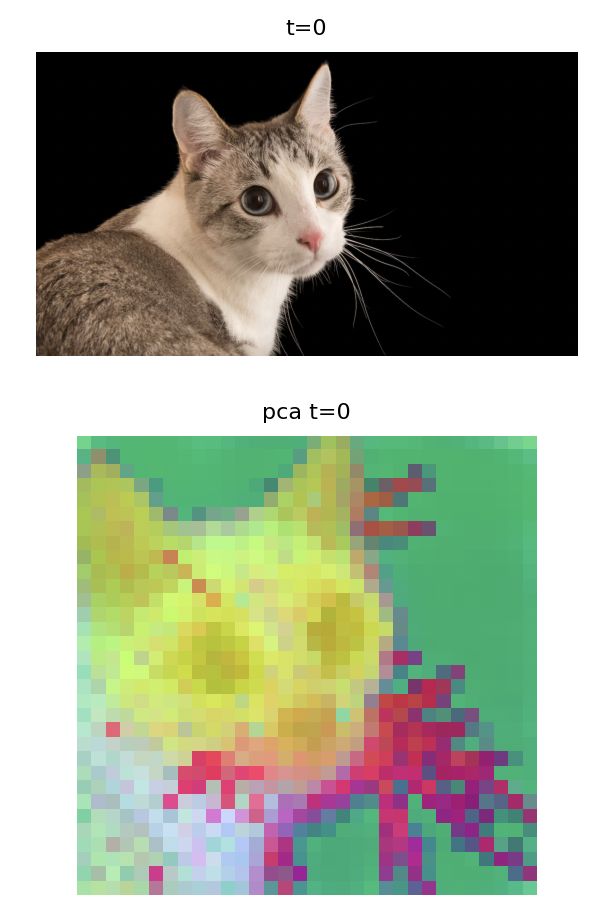
- tested V-JEPA2.1
Successes:
- got V-JEPA2.1 working
- 
Failures:
- N/A
Next steps:
- make LeWAM architecture
Time spent: 6 hours
February 22 2026 - ACT Policy training
Goal: Try training a lerobot act policy
Work Done:
- Got familiarized with lerobot policy training parameters
- Created automated scripts for training and uploading models on vast.ai instances
- Trained ACT policy, available at https://huggingface.co/ehalicki/zima-rubiks-cube-act (most likely not functional yet)
Successes:
- Automated scripts work, full policy training pipeloine works
Failures:
- very slow training (~4 hours or more for the recomended 30k steps on a A4000)
- How long would a VLA take to train with these kinds of budgets???
Next steps:
- Test policy deployment with remote policy server
- Collect more episodes
Time spent: 3 hours
February 15 2026 - restarting zima in Switzerland
Goal: Test zima hardware to see if it still works after being shipped to europe. Come up with next actionable steps for policy implementation
Work Done:
- connected to zima using lerobot interface developed during winter break, tested networking and hardware functionality by performing some teleoperated demonstrations
- Tried training ACT policy using LeRobot implementation briefly, with successful start (i terminated the run early due to running on laptop hardware, will resume the experiment remotely soon)
- Started drafting general statement of purpose for graduate school applications
- 
Successes:
- all hardware and networking work, just slightly more inconvenient due to enterprise network security on eduroam
- Moved to Zurich for ETH exchange and starting robot learning class tommorow
Failures:
- Gripper pad detached and i have no way of reconnecting it until i go to the ETH project house
Next steps:
- Read and annotate ACT paper
- print at ETH
- Resume ACT policy training
- get inspiration for further direction from ETH Robot Learning course
- reprint housing cover and reattach gripper pad at ETH project house
Time spent: 1 hours
Jan 25 - Jan 27 2026 - Zima teleoperation tuning and dataset collection
Goal: Test dataset recording, replay, upload, visualization and teleoperation smoothness
Work Done:
- Tested and tuned full dataset collection pipeline, from teleoperation to online upload and visualization
- Got a lead on lerobot ACT policy observation format
- expects observation.images.{xyz}, however, inside the observation features dictionary, it is not required to use the .images format, lerobot automatically figures out which entries are images
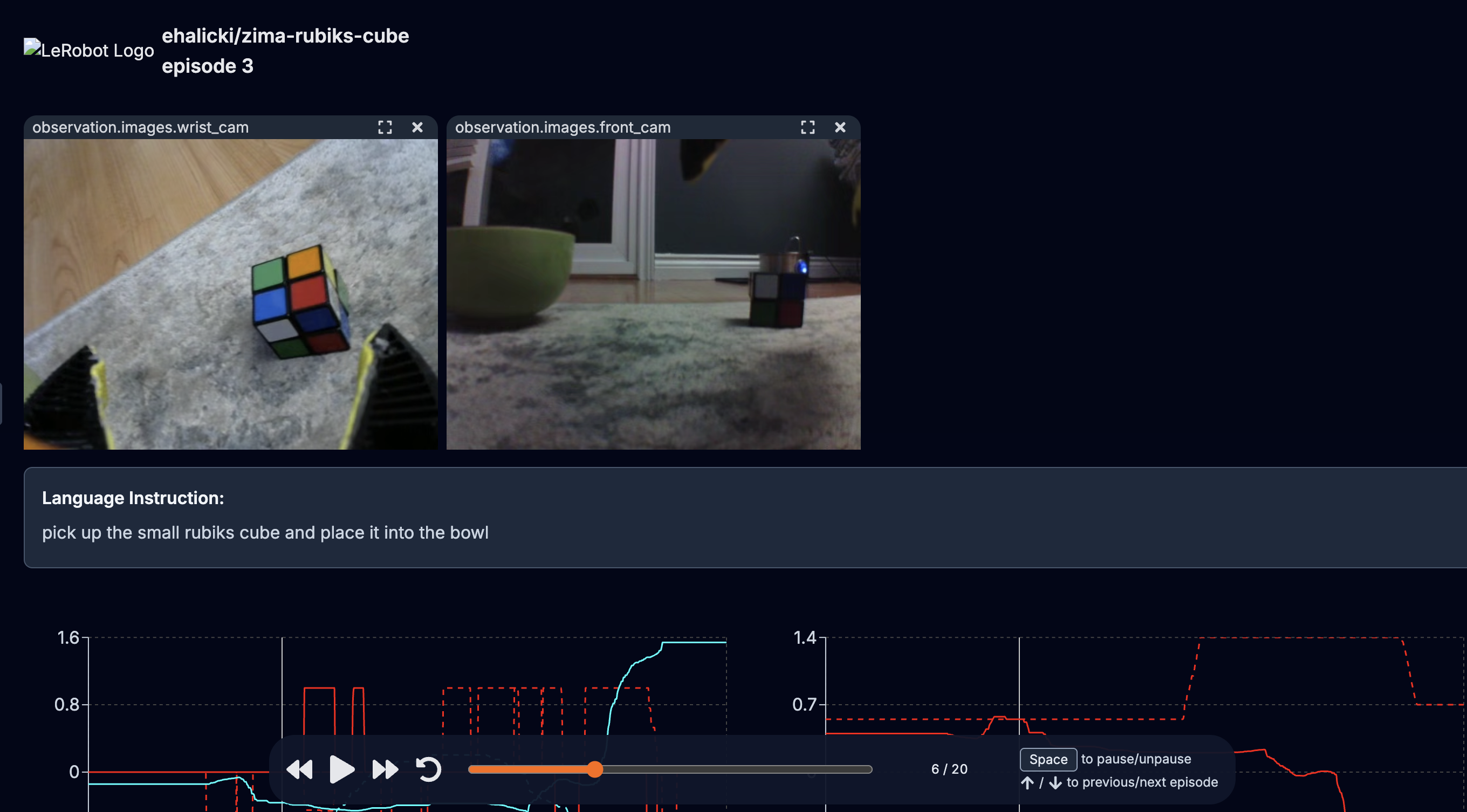
- Collected 10 clean episodes of teloperated test ""
- 
Successes:
- test dataset uploaded at https://huggingface.co/datasets/ehalicki/zima-rubiks-cube-test
- full dataset at https://huggingface.co/datasets/ehalicki/zima-rubiks-cube
- can be visualized online at https://huggingface.co/spaces/lerobot/visualize_dataset?path=%2Fehalicki%2Fzima-rubiks-cube%2Fepisode_0
Failures:
- arm kinematics system still has some weird lock ups where it stops responding to new commands because of high error due to large joint state changes
- can increase or remove error threshold?
- can decrease joint error weight?
Next steps:
- Move to switzerland
Time spent: 2 hours
Jan 23 - Jan 24 2026 - Fixing electrical and firmware issues
Goal: Resume zima project, fix motor driver, arm issues, and plan next steps
Work Done:
- installed new motor driver after short circuiting the last one
- debugged intermittent joint failures, most likely due to brown outs from limited max current on buck converter
Successes:
- Entire zima platform should be working now, lerobot interface done, firmware issues resolved, electrical issues resolved
- Found firmware bug causing excessive arm jittering, fixed by rate limiting servo updates to 50hz
Failures:
- Spent more time than expected on fixing joint failures
Next steps:
- Record task demonstrations, replay to test reproducibility
- figure out how to format observations to be compatible with lerobot act policy
Time spent: 3 hours
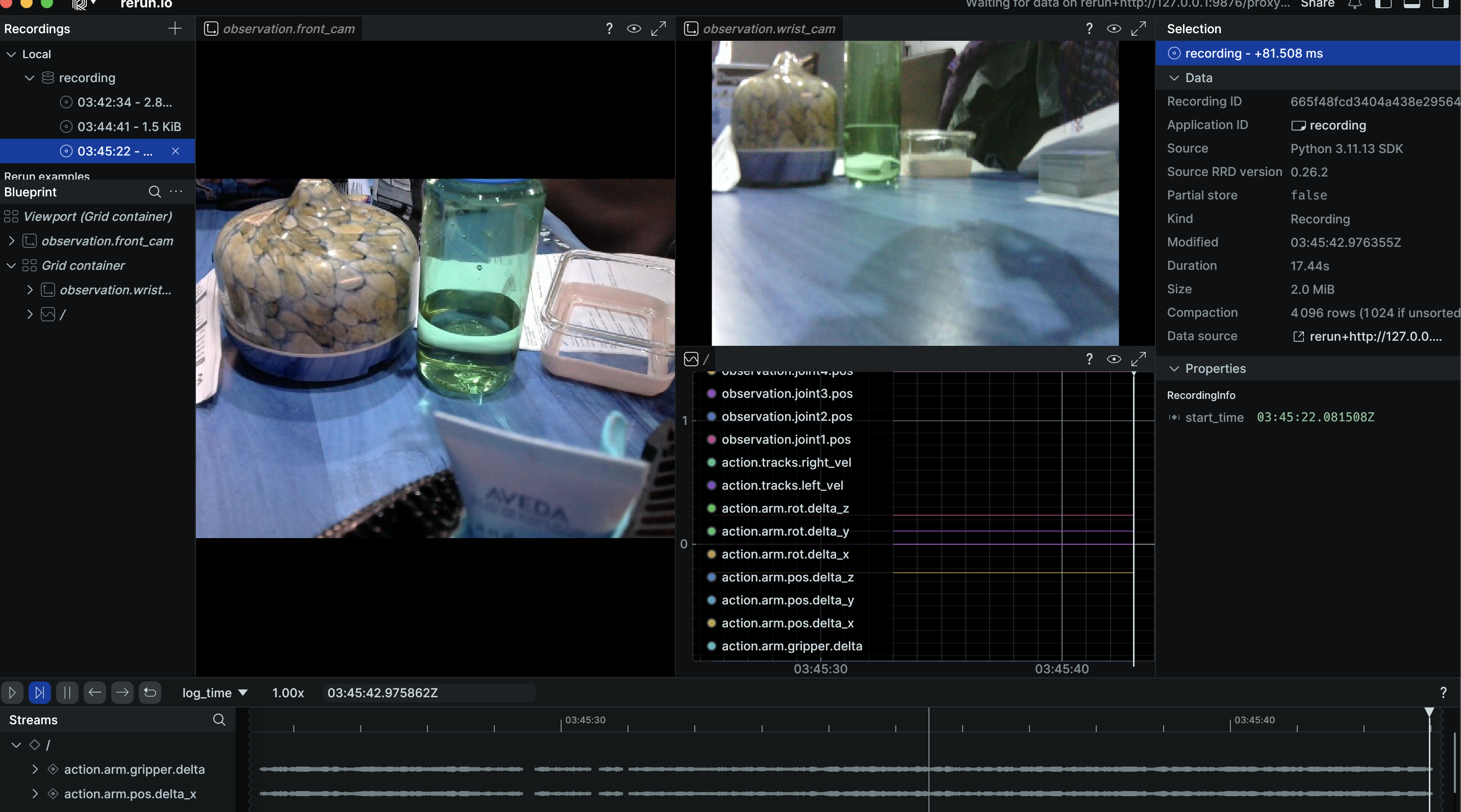
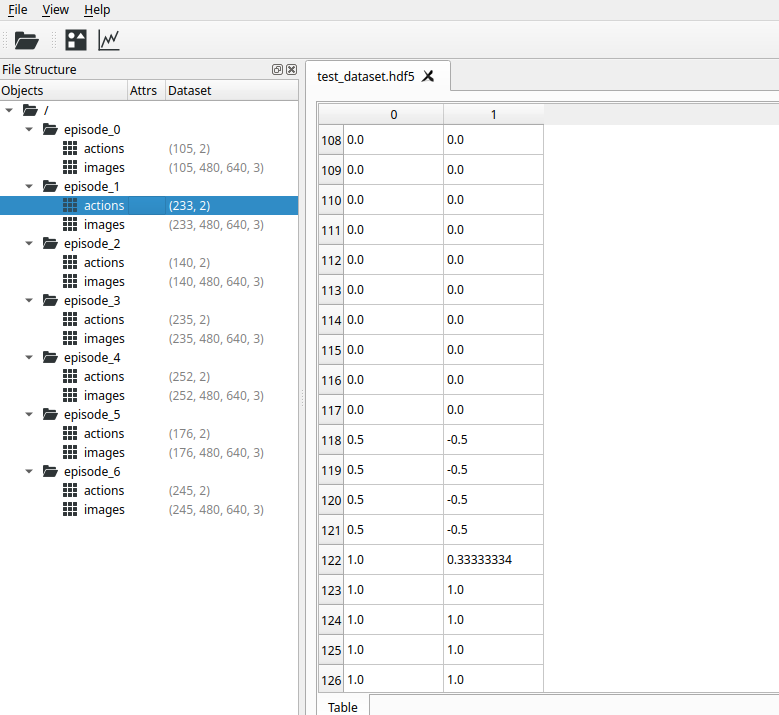
Jan 3 - 4 2026 - lerobot dataset collection testing
Goal: Create lerobot teleoperation interface and test dataset collection
Work Done:
- Tested zima_robot lerobot interface
- implemented and tested lerobot teleoperation ps3 controller interface
- recorded sample lerobot dataset using lerobot tools
- 
Successes:
- Teleoperation, robot interface, dataset collection, and episode replay all work
Failures:
- Zima died due to an accidental short circuit of a buck converter
- replacement part ordered and arriving Jan 5th 2026
Next steps:
- continue reading vla literature
- apply to summer research fellowships before continuing with zima project
- collect dataset and train ACT policy for single task
- try to find out cause of intermittent arm jitter if it becomes an issue
Time spent: 6 hours
Dec 29 - Jan 2 2026 - LeRobot interface implementation
Goal: Implement Zima LeRobot interface and continue VLA readings and implementation planning
Work Done:
- installed lerobot and finalized communication architecture design
- looked for observation and action format requirements for various policies supported by LeRobot
-
- implemented tcp server interface and LeRobot
Successes:
- got a lead on figuring out how observations and actions get adapted to policy formats
- https://huggingface.co/docs/lerobot/en/introduction_processors
Failures:
- Still cant figure out how the data gets converted from robot format to batched policy formats, need to find a better example
Next steps:
- figure out what observation and action format ACT needs in LeRobot
- adjust zima robot output? Maybe this should be adjusted in post processing on a per policy basis since most will have different requirements?
Time spent: 5 hours
Dec 11 - Dec 28 2025 - Exams and data collection improvements
Goal: Lock in on finals and improve Zima data collection system to include all relevant manipulation data (arm delta commands, joint state, multi camera, etc.)
What I did:
- explored hugging face LeRobot repo
- https://github.com/huggingface/lerobot
- https://huggingface.co/docs/lerobot/index
- Lots of standardized systems available
- dataset format (already connected to pytorch)
- async_inference server
- policy training
- read lerobot dataset reference
- https://huggingface.co/docs/lerobot/lerobot-dataset-v3
- read lerobot hardware integration guide
- https://huggingface.co/docs/lerobot/integrate_hardware
- Continued reading NLP and CV foundational papers
What worked:
- Locked in on exams
- Got through entire CLiP paper in one sitting
What failed:
- N/A
Key learning:
- Lots of dirty data is better than a little clean data
- LeRobot provides a Robot base class for custom hardware
Next session:
- Begin writing Zima LeRobot interface
- Expose a non ros2 interface? (TCP probably)
- on board computer runs ros2 and tcp interface
- external applications can interface with zima over ros2 (ex. run teleoperation on mac, run )
Time spent: 5 hour
Dec 9-10 2025 - Inverse kinematics tuning
Goal: Get a functional / smooth arm control system working for zima
What I did:
- read http://www.incompleteideas.net/IncIdeas/BitterLesson.html (Sutton, 2019) + Era of experience paper
- interesting perspective on the research direction for ai. Interesting how it ties into embodied systems
- Improved error estimation with joint difference error penalty (current_joint_state - next_joint_state)
- Removed kd_tree warm start once a current_joint_state is provided
- visualized arm and compared to real life. Improved arm model to match real world more closely
What worked:
- Got much smoother arm movement after various kinematics system tweaks. Fully integrated with ros2 control system.
- Having a more accurate arm model (tweaking link/joint transformations) improved stability as well
-
What failed:
- Still some slight jitter and inconsistency at extreme arm angles (close to workspace boundary especially with high z), but overall much better than initial versions.
Key learning:
- Modelling accuracy is quite important
- starting point / warm start of gradient descent algorithm is quite important
Next session:
- Begin writing data collection code for more complex demos
- arm + tracks + multi camera data
- finish and test multi camera driver
Time spent: 4 hours
Dec 8 2025 - Zima arm kinematics testing
Goal: Polish and test arm kinematics on hardware
What I did:
- Added joint and workspace limits
- Further tested ik solver in simulation
- Completed ros2 connected arm controller
- Sucessfully Tested ik on hardware
- Debugged firmware issues
- needed to downgrade esp32 board library to 2.0.x
- Found bug in the jacobian estimation code
What worked:
- 
- Teleoperated sample pick and place tasks (eg. pick up and stack rubiks cube)
- fixing jacobian estimation bug improved stability a little, but still lots of jumps in the solution space
- need to add penalty term for large changes in the joint state
What failed:
- IK solver good in simulation and fast, but certain awkward angles in real life cause jittery movement
Key learning:
- IK solver on its own can be a little unstable
- Good idea to have ai proofread your code
Next session:
- Add penalty for large joint state changes in the error calculation
- Test IK in real life again
- Begin writing data collection code for more complex demos
- arm + nav + 2 camera data
- finish and test multi camera driver
- visualize arm side by side with real life to see modelling accuracy
Time spent: 6 hours
Dec 7 - Zima Arm kinematics (pt. 2)
Goal: Complete second iteration of zima arm kinematic solver
What I did:
- wrote a kd tree and gradient descent based ik solver for zima's arm
What worked:
- Gained a much better understanding of forward kinematics and homogenous transformation matrices
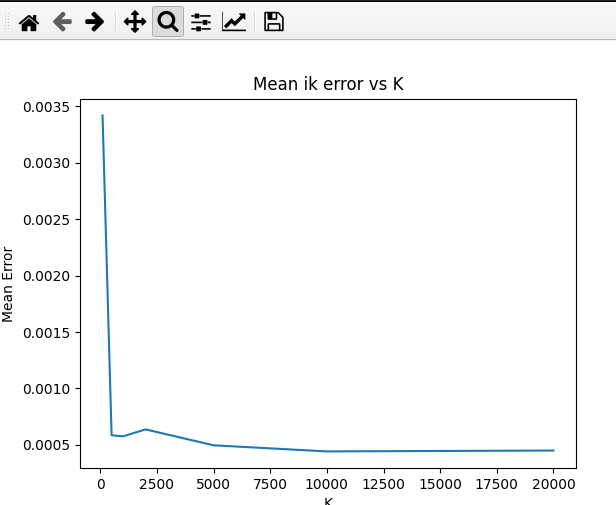
- Evaluated inverse kinematic solving performance of kd tree approach (visualized below)
- 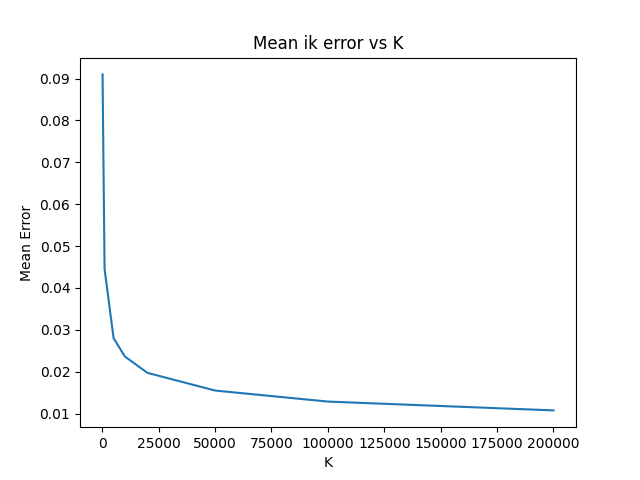
- algorithm performance improves logarithimically with the amount of points sampled for the kd_tree
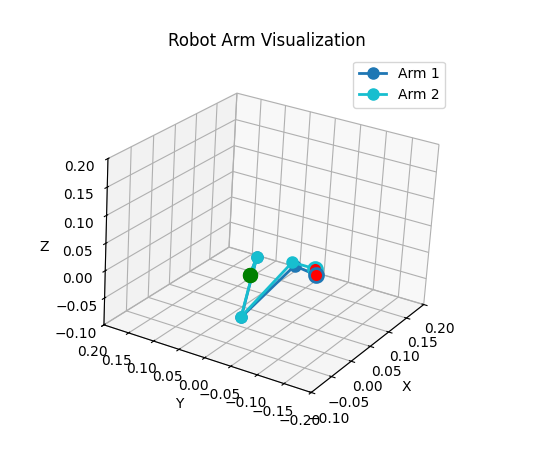
- Even without coordinate descent, the algorithm is able to find good solutions (see below). I evaluated this by generating random joint states, then calculating their end effector pose, and passing that into the ik algorithm
- Random arm pose (arm 1) vs ik solution (arm 2)
- 
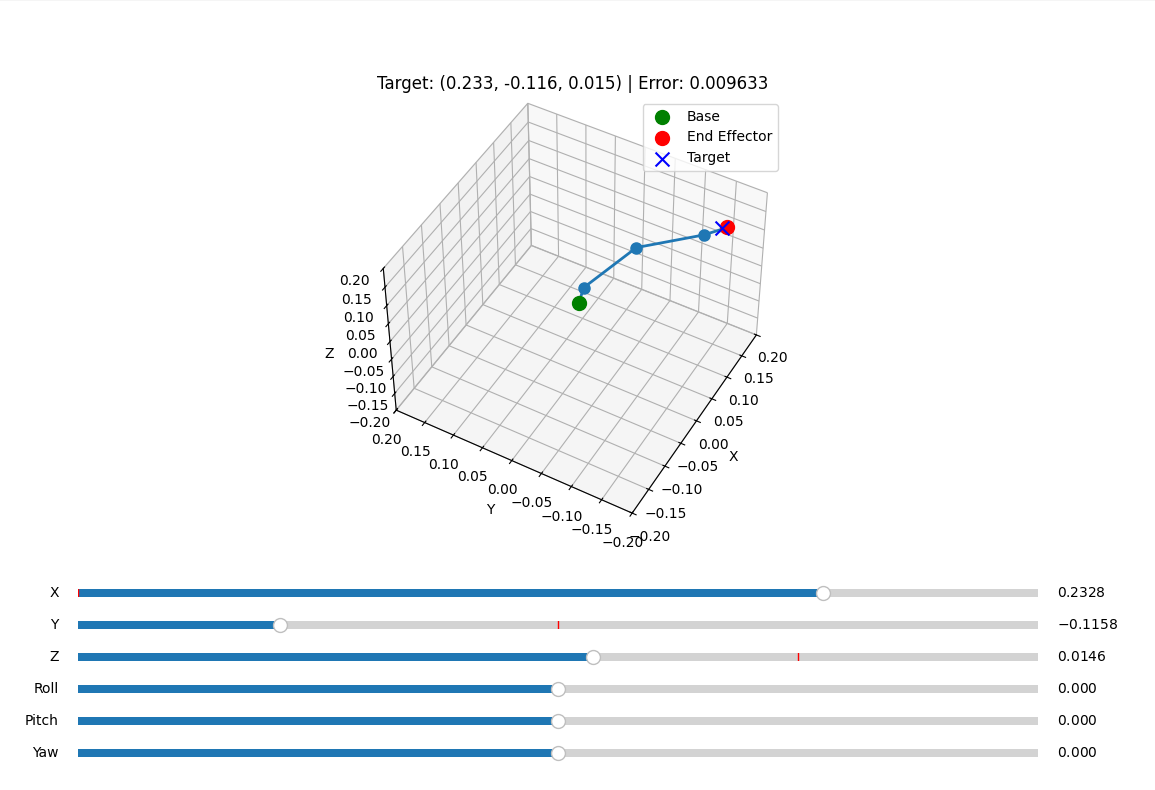
- Tested finding ik solutions for various realistic end effector poses
- 
- Implemented Jacobian based solver, improving smoothness of solution space and reducing requirement for large pre generated estimates
- 
What failed:
- Accidentally only generated angles from 0-pi causing weird solutions once i started testing solving arbitrary xyzrpy coordinates
- fixed by generating within correct angle constraints
Key learning:
- Became much more familiar with kinematic chains
- potential future experiment: how well does this simple ik method hold up in under-constrained spaces (eg. 7dof arm)
- Cyclical Coordinate Descent is an alternative to gradient descent
- Jacobian based solver is not as complicated as i expected
Next session:
- Concrete next step
- Specific thing to try
Time spent: 10 hours
Dec 6 2025 - Zima arm kinematics
Goal: Start setting up forward and inverse kinematics solving for zima arm
What I did:
- used http://www.pabr.org/sixlinux/sixpair.c to set bluetooth host mac of ps3 controller to raspi mac
- gave up, opted for wired control for now
- Started working on forward and inverse kinematic solver for arm
What worked:
- Nothing
What failed:
- ps3 controller refused to connnect over bluetooth
- spent like an hour debugging
Key learning:
- FK is just a chain of transformation matrices being multiplied
Next session:
- Continue ik and fk setup
Time spent: 6 hours
Dec 5 2025 - Zima Arm Validation
Goal: Test zima arm ability to pick up various objects, + clean up internal wiring
What I did:
- watched a recent robotic learning phd defence from CMU
-
- Tested teleoperating zima's arm for simple manipulation task (pick up rubiks cube)
- Cleaned up internal wiring
- Decided i will be working towards turning zima into a technical writeup for arxiv preprint
- https://info.arxiv.org/help/submit/index.html
What worked:
- Arm capable of picking up various objects much better than before
What failed:
- Battery died during testing, not surprising but should make battery monitor
Key learning:
- looks like you publish many papers during phd, and you start shaping a research portfolio, not just a single project
Next session:
- implement more robust arm teleoperation
- continue reading vla literature (vit, clip, llava, rt1, rt2, pi0)
- start thinking of potential research question
Time spent: 1 hour
Dec 4 2025 - Finishing zima arm rework
Goal: Have a fully functioning gripper capable of lifting medium sized objects (~0.5kg max, 10cmx10cmx10cm)
What I did:
- Finished designing, printing, assembling, and testing zima's new arm
- note: arm has been reduced to 4DOF arm + 1DOF gripper (5DOF total), down from previous 5DOF arm + 2 DOF gripper (7DOF total)
- Tested and iterated on new camera mount, ensuring gripper + workspace is in frame
What worked:
- Zima with new arm
- 
- *Wrist mounted camera POV
- 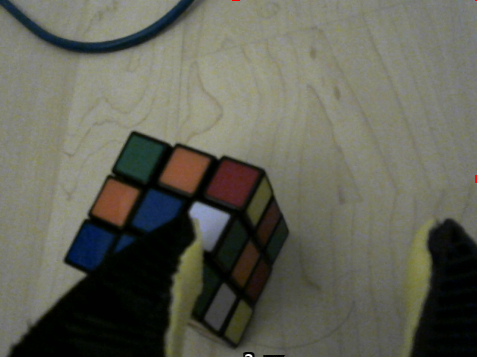
What failed:
- wrist camera FOV is quite low (~60 degrees), resulting in camera mount needing to be quite far back from the gripper
Key learning:
- N/A
Next session:
- Begin PCB redesign
- Make a list of all new features needed (eg. battery monitoring, oled screen?)
Time spent: 8 hours
Dec 3 2025 pt. 2 - completed zima gripper redesign
Goal: Finish designing new zima gripper and start 3d printing
What I did:
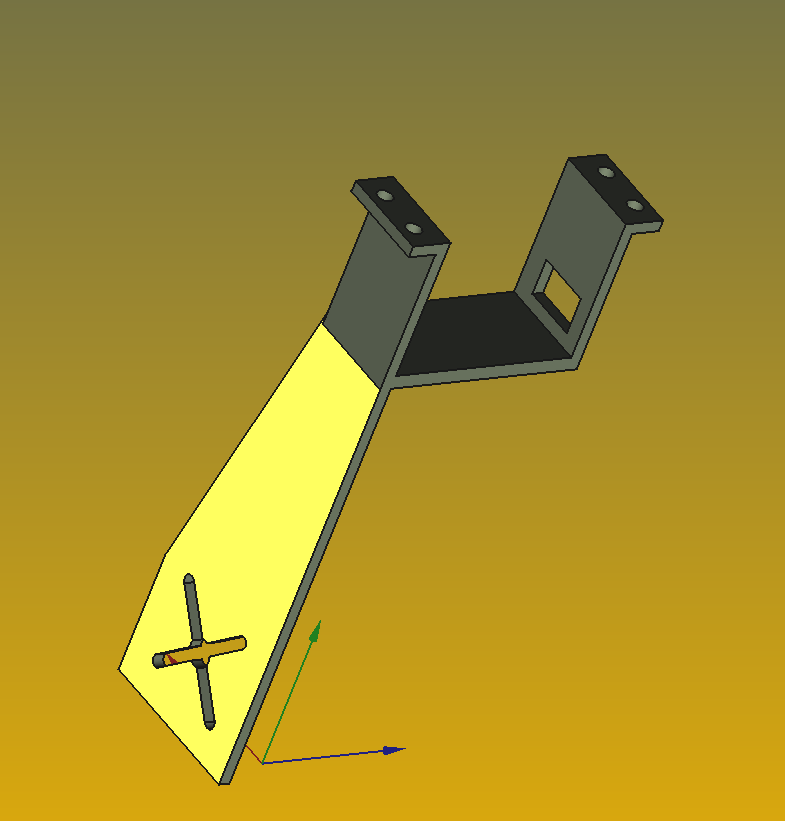
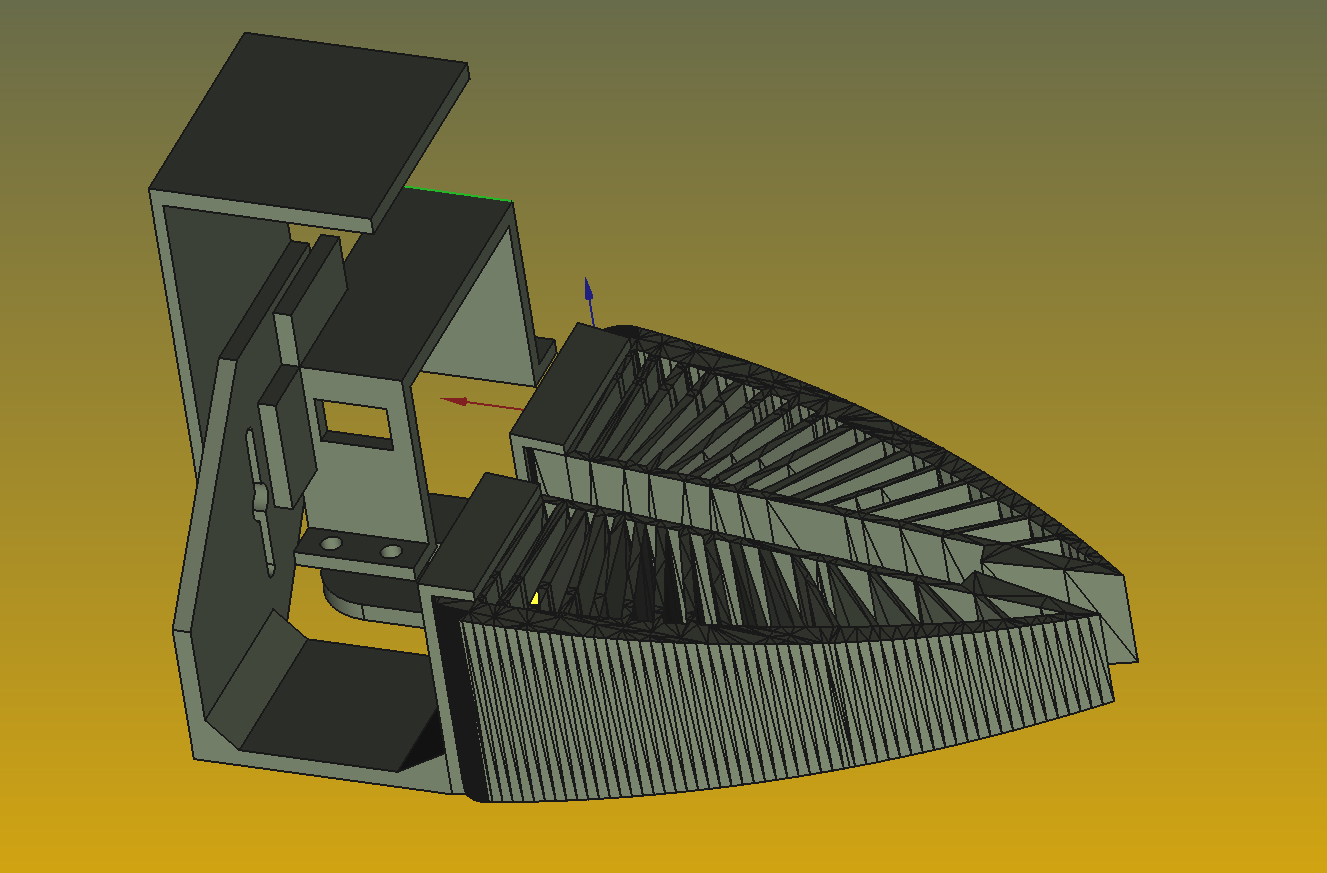
- Finished designing new gripper with camera mount and compliant fingers
- finished designing new wrist to hand joint, increasing total arm reach
What worked:
- 
- 
What failed:
- Gripper design took longer than expected, haven't had a chance to start on electronics pcb redesign yet
Key learning:
- N/A
Next session:
- Finish printing and assembling new arm
- Begin new electrical schematic
- Start figuring out how to tele-operate with no leader arm
Time spent: 2 hours
Dec 3 2025 - Math 307 project
Goal: N/A
What I did:
- Created an image compression script using the singular value decomposition of an image for Applied Linear Algebra course (UBC-O MATH 307)
What worked:
- 
What failed:
- N/A
Key learning:
- N/A
Next session:
- N/A
Time spent: 1 hour
Dec 1 2025 pt. 2 - Devlog CI/CD + Zima internal electronic revamp planning
Goal: Get devlog to auto upload to eryk.ca + start on KiCAD electrical schematic + pcb design
What I did:
- created new ci/cd and markdown parsing code to eryk.ca repo
- downloaded KiCAD and started drawing up zima internal electronic schematics
What worked:
- Automatic deployment works as expected, just some small formatting hickups with youtube videos and images
What failed:
- Nothing
Key learning:
- PCB and electrical schematic design looks like it'll take some time
Next session:
- Continue electrical schematic + PCB design
Time spent: 2 hours
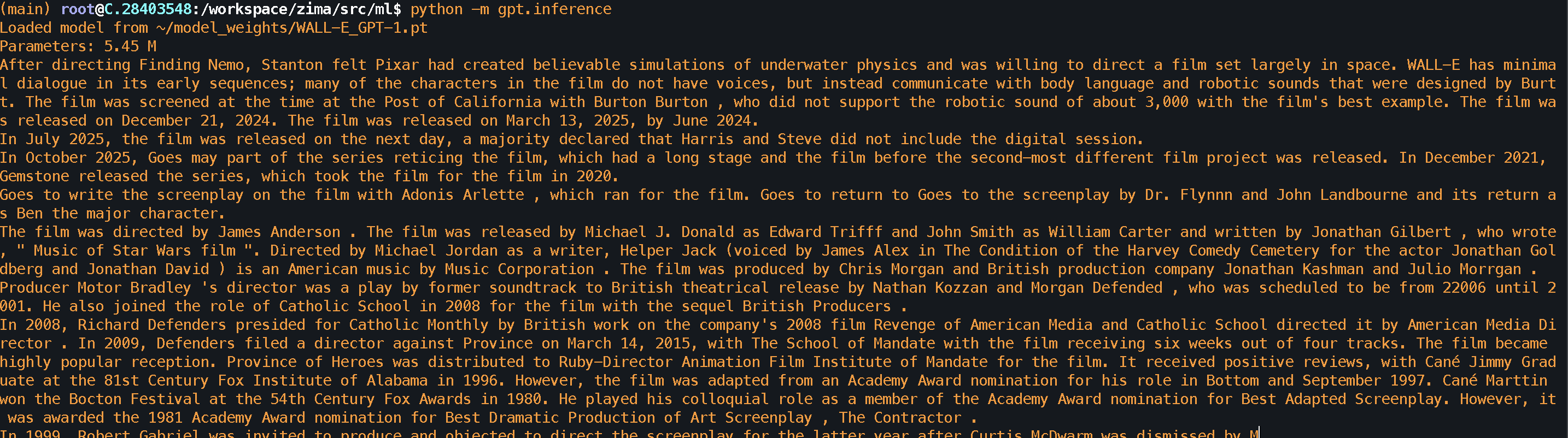
Dec 1 2025 - Smaller model experiment
Goal: Train a smaller model with same dataset to see if overfitting is reduced
What I did:
- Trained a smaller (5M param) model on the 200M word wikipedia dataset
- Learned a bit more about LLM scaling laws
- Continued reading transformer literature (ViT, CLiP, etc), working up to VLA work
What worked:
- Model achieved nearly identical performance despite having 6x less parameters and training for less time
- Model was able to capture syntax quite well, and some semantic meaning of words (Movies, Directors, dates, countries, etc.)
- 
What failed:
- Output still fairly incoherent. No long range relationships or intelligent output. Only basic english patterns present in output (correct spelling, nouns and verbs used correctly, very few made up words)
- Even as loss went down after epoch 3-5, model coherence seemed to decrease
- most likely overfitting on my small dataset
Key learning:
- Model of this scale (10^6 params) seems to only be capable of learning syntax and basic semantics
- even the absolute smallest, most compact models (eg. Google Gemma 3 270M-27B) are in the order of 10^8 - 10^10 params
- More epochs and excess model capacity can lead to overfitting quite quickly
- More recent LLM's are increasing token : param ratio, with Gemma 3 270B using 22,000 : 1 ratio
- what does this mean for my robotics projects? How does this scaling compare in vision tasks? Robotics tasks?
- Training ViT and LLM heads from scratch for VLA will be a waste of time, need to fine tune instead or just use as fixed feature extractors
- Zima real world task performance could be very strongly affected by lack of real world data (only 40 trajectories)
-
Next session:
- No more GPT training, move back into robotics work
- Continue reading VLA literature
Time spent: 2 hours
Nov 28 2025 - Larger model training
Goal: Train larger model on larger dataset for longer, trying to acheive more coherent output
What I did:
- Updated wikipedia scraper algorithm to use priority queue instead of greedy search
- Updated tokenization and data preprocessing system to allow for more efficient retokenization of large datasets
- Scraped 200M word dataset and trained 30M parameter model on cloud
What worked:
- 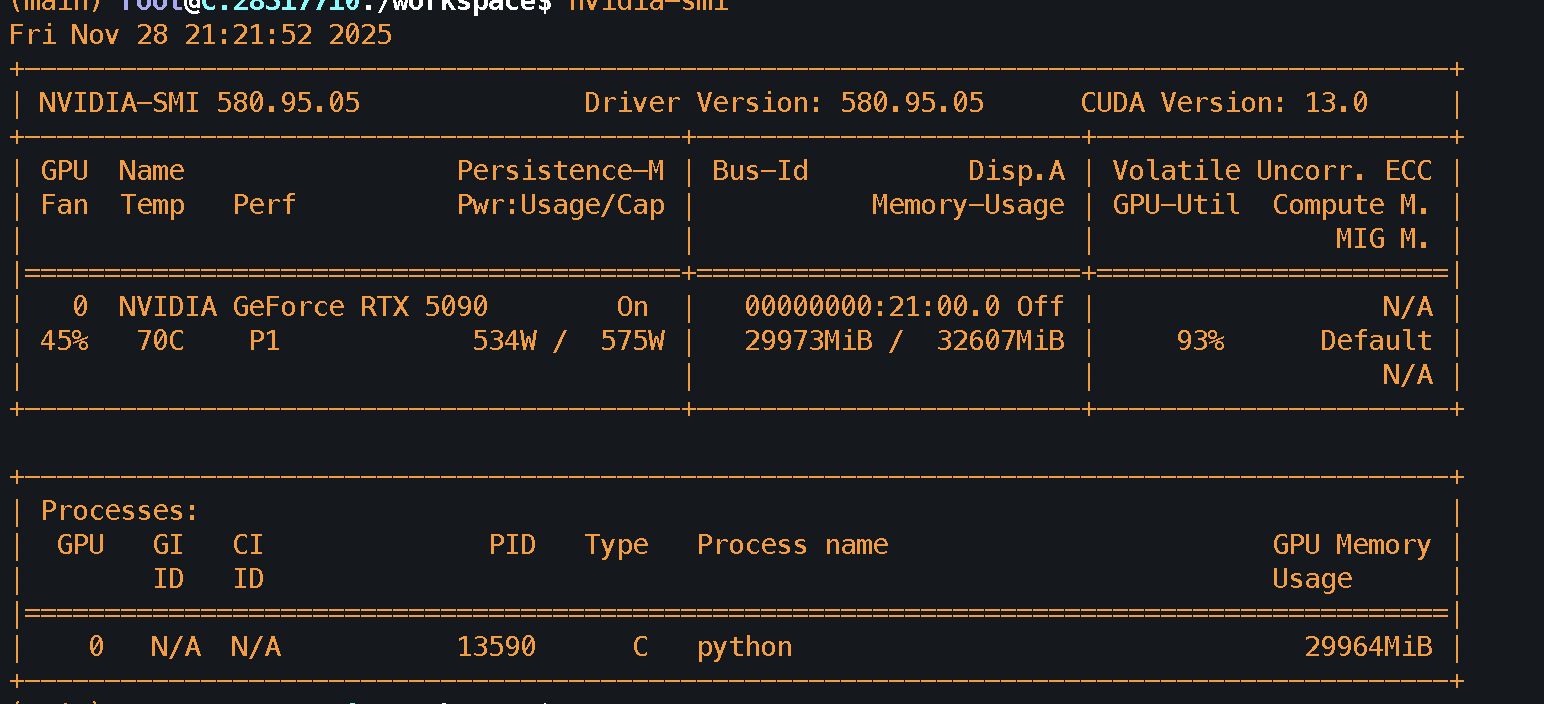
- Got Vast.ai training instance going with full utilization of 5090 GPU
- estimated training time ~30 hours for 20 epochs,
What failed:
- Tuning training config to fully utilize GPU + have decent model size took a few retries
- even with 8 hours of scraping, could only get ~200M words.
Key learning:
- Data requirements for transformer seems very high, even a 10M word dataset from yesterday wasnt very good
- I'm starting to see why we use pre trained weights for VLA models (and others)
- May want to create a script that automatically finds a good batch size (~95-99% VRAM utilization)
- Would save some time and money when dealing with larger cloud instances
Next session:
- Plan out project direction considering new knowledge
- Test model inferencing!
Time spent: 4 hours
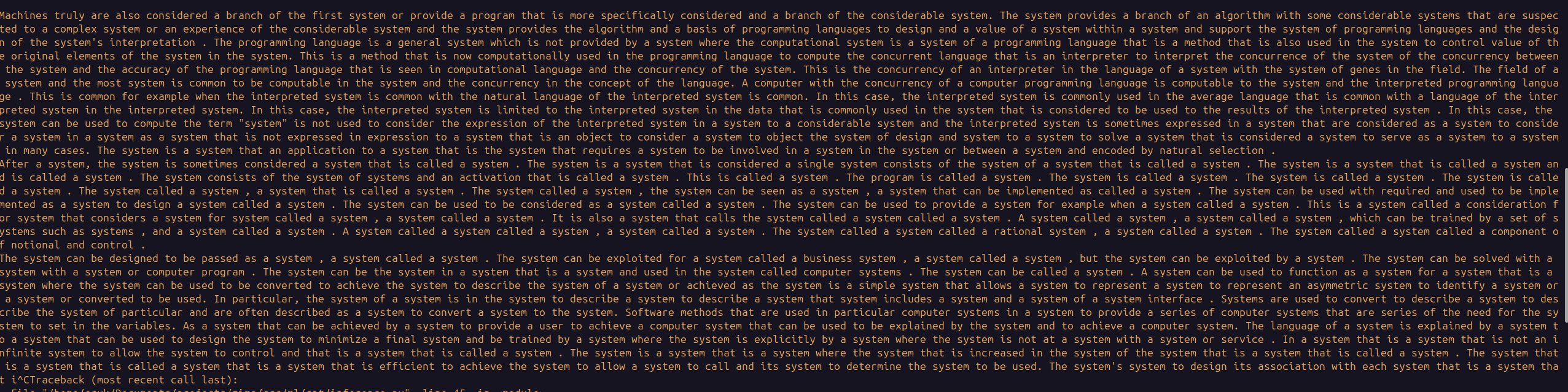
Nov 26 27 - GPT Training, EUREKA! First coherent sentences generated
Goal: Debug model output and train semi coherent model
What I did:
- Debugged model training loop
- implemented automated, dockerized training setup
- Trained first coherent model on Vast.ai
- Set up automated aws s3 dataset fetching and model weight saving
- Started overnight wikipedia scraping job to collect 75000 pages or ~300M words
- Wasted time trying to get the wikipedia scraper to be faster
What worked:
- Vast.ai training on 1 4090 cost less than 1$ and took around a hour to acheive log loss ~1 on a 5000 document dataset (10M words)
- 
What failed:
- Wikipedia scraper slow, cannot figure out how to optimize it
Key learning:
- One insight that matters
Next session:
- Train on vast ai multi gpu machine using >100M word dataset
- update code to use Distributed training setup
Time spent: 8 hours
Nov 25 - GPT architecture
Goal: Build and test GPT architecture (not training yet)
What I did:
- Finished attention head design
- finished implemeing full GPT architecture
- Implemented basic tokenizer and model inference system
What worked:
- Good progress on model development
- understanding positional encoding pretty well
- 
- Got random output, first AI slop generated!
- 
What failed:
- Nothing major
Key learning:
- Lots of pytorch familiarity, working with no ai assistance
Next session:
- reconsider inverse vocabulary mapping system design
- make training loop
Time spent: 4 hours
Nov 24 2025 - Starting transformer implementation
Goal: Begin implementing transformer paper + gpt1 in pytorch
What I did:
- Revisted attention is all you need
- learned about layer normalization
- implemented attention head from scratch in pytorch
What worked:
- attention head shapes look correct
- understanding of transformer arch is solidifying
What failed:
- Slower at hand writing pytorch than I'd like, but also delayed by trying to fully understand the architecture
Key learning:
- In the decoder, we mask the attention matrix pre-softmax so that the output is autoregressive
- need to pad outputs to ensure entire batch is of the same shape, because thats the only way to make gpu run the computations in parrallel
Next session:
- Implement full transformer block
- Implement GPT model
- Port wikipedia data scraping from wikipedia graph project for data collection
Time spent: 3 hours
Nov 23 2025 - Real world robustness improvements
Goal: Make model reliably execute search and approach strategy in real life
What I did:
- Collected more real world demonstrations
- evaluated model in real world again
- optimized data loading speed by maxing out cached episodes + parallel workers
- added partial action chunk execution to try smoothing out movements
What worked:
- Model performed better in real life with image history + larger action history
- Training on all data for 2 epochs, then fine tuning on one epoch of only real world data had good results
-
- Model able to reliably execute search and approach strategy
- ~70-80% completion rate for in distribution situations
- ~20-30% completion rate for out of distribution situations

What failed:
- Model struggles to detect objects far from camera
- almost certainly due to low resolution, a rubiks cube ~1.5 meters from the camera is ~10 pixels wide, all unique features probably unrecognizable at this resolution
- Model struggles in out of distribution settings
- when the background is very different from most of the dataset, sometimes obvious cube detections in the camera do not trigger an approach movement
- Can probably be resolved by using a more diverse dataset, and a more generalizable model
Key learning:
- More data + more context for model + cleaner visual input -> acceptable model performance
Next session:
- Begin implementing transformer in pytorch, and continue reading papers
- create a battery voltage monitoring system (need to update and reflash MCU firmware)
Time spent: 6 hours
Nov 22 2025 - Real world policy evaluation
Goal: evaluate the policy in real life and iterate
What I did:
- reduced max wheel speed and compromised on camera resolution - fps tradeoff, reducing motion blur
- tried on device inference - fail
- added frame stacking / image history input to model, hoping to improve real world performance
What worked:
- fine tuning on just real world data for a few epochs improves real world performance noticeably
What failed:
- wasted more time trying to get camera driver to work, to no avail
- on device inference caused brownout?
- image stacking is starting to eat into my gpu memory, had to reduce batch size to 32 to not run out of mem
- Model with shortened action history (4) was not able to do proper search behavior
Key learning:
- Real world is difficult
Next session:
- Collect more real world data
- test new image stacked model in real life
Time spent: 4 hours
Nov 21 2025 - Real world generalization
Goal: Collect more real world data and continue model fine tuning
What I did:
- Collected 20 more episodes of real world data, with varying scene setups and starting positions
- Further fine tuned model using 30 episodes of real world data
- Evaluated model in real life, mixed results
- motion blur in real life but not in simulation
- Tried fixing motion blur by reducing exposure time
What worked:
- Model trained with both real world and sim data was able to still complete tasks in sim
- data mixture is very sim heavy though, (210 vs 30 episodes) so this isnt too unexpected
What failed:
- model may be overfitting to the real world dataset, training and test accuracy very high (>90%) but task completion rate is mediocre
- funny artifact, policy seems to have overfit to a handful of training examples where the rubiks cube was placed near a carton of soy milk, and since the soy milk carton is more visible than the cube, the model gets tripped up and approaches the carton of milk sometimes
- Motion blur is harming model performance significantly in real life
- Rubiks cube is almost imperceivable at a distance
- Struggling to set manual exposure time successfully. Cameras not listening
- Battery died at end of session
- multi meter battery is dying, so readings are inaccurate, so have no idea if the BMS low-voltage protection kicked in
Key learning:
- Starting to really see the real world noisiness, simulation is very trivial compared to irl
Next session:
- create a battery voltage monitoring system (need to update and reflash MCU firmware)
- evaluate sim+real data policy in real life
- Add motion blur to the sim data?
- try debugging camera blur again
- set exposure time low and check if performance improves
- try mjpg 320x240, but moving the crop to center somehow
Time spent: 4 hours
Nov 20 2025 - Quick bugfix
Goal: Fix model inference jitter bug
What I did:
- debugged model inference, removing inference jitter
- turned out to be teleop_controller sending competing motor commands at control rate
What worked:
- {add photo of zima irl}
- movement jitter gone, only remaining jitter is from model inference now
What failed:
- policy task completion rates are noticeably lower in real life than simulation still
Key learning:
- async control has extra difficulties
Next session:
- Collect more irl data
- Add more sim data augmentation
Time spent: 1 hours
Nov 19 2025 - 3D printing and REAL WORLD task completion!!!
Goal: Print a backing for zima's body and begin collecting real world data
What I did:
- Reinstalled Freecad and moved cad models into the zima repo
- Set up 3d printer again
- Collected 10 episodes of real world data
- Fine tuned sim model using real world data
- ~35 epochs with 3000 samples, reduced LR to 1e-6 for resnet and 1e-5 for action head
- Connected main computer to wifi, allowing for tetherless operation
- Evaluated real world model
What worked:
- Printer setup went smoother than usual
- Havent forgotten how to use FreeCAD, so designing the backing wasn't too bad
- 
- Backing printed successfully, all tolerances are fine
- After fine tuning on 10 episodes of real world data, the robot was able to successfully complete the task in the real world with an acceptable success rate (~30%), mainly succeeding in very controlled environments (rubiks cube against white wall backdrop)
What failed:
- Random 3d printer raspberry pi crash (possible brownout?)
- Accidentally stuck a cutter in the printer head while printing, so the backing turned out a ltitel lopsided, but still works just fine
Key learning:
- You can use "Part Binders" in FreeCAD instead of copying the entire part reference over when creating separate parts
Next session:
- Collect more real world data, fine tune on larger dataset (increase test data split size to 20% as well)
- vary the background the cube is in more (is the resolution just too low atp?)
- reduce the frame rate of the collected real world data, undersample it
- evaluate in real life after ~50 episodes are collected, document failure modes
Time spent: 4 hours
Nov 18 2025 - Sim 2 real prep
Goal: begin testing sim model performance on real hardware, and set up pipeline for real world data collection
What I did:
- ported the nn_conroller class from the mujoco simulator to a ros2 node connected to the existing hardware interface code
- polished the camera driver to downscale images before publishing to reduce network traffic
- bugfixed some hardware interfacing issues
- tested the sim rubiks cube navigation model with no real world data
- ported the web teleoperation code to a ros2 integrated controller
- Set up real world dataset collection pipeline
What worked:
- 
- 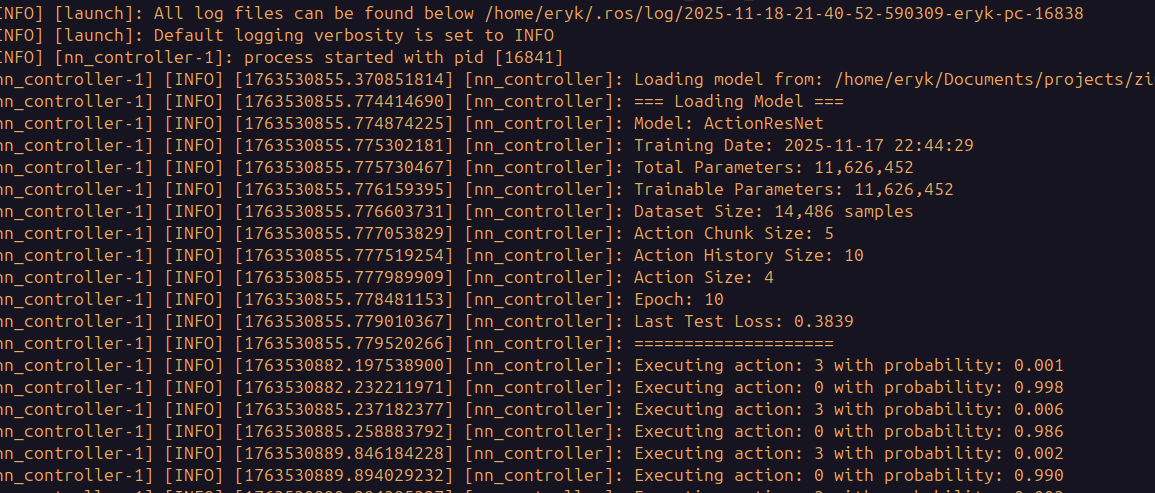
- Model inference worked and the full hardware interface works as expected
- 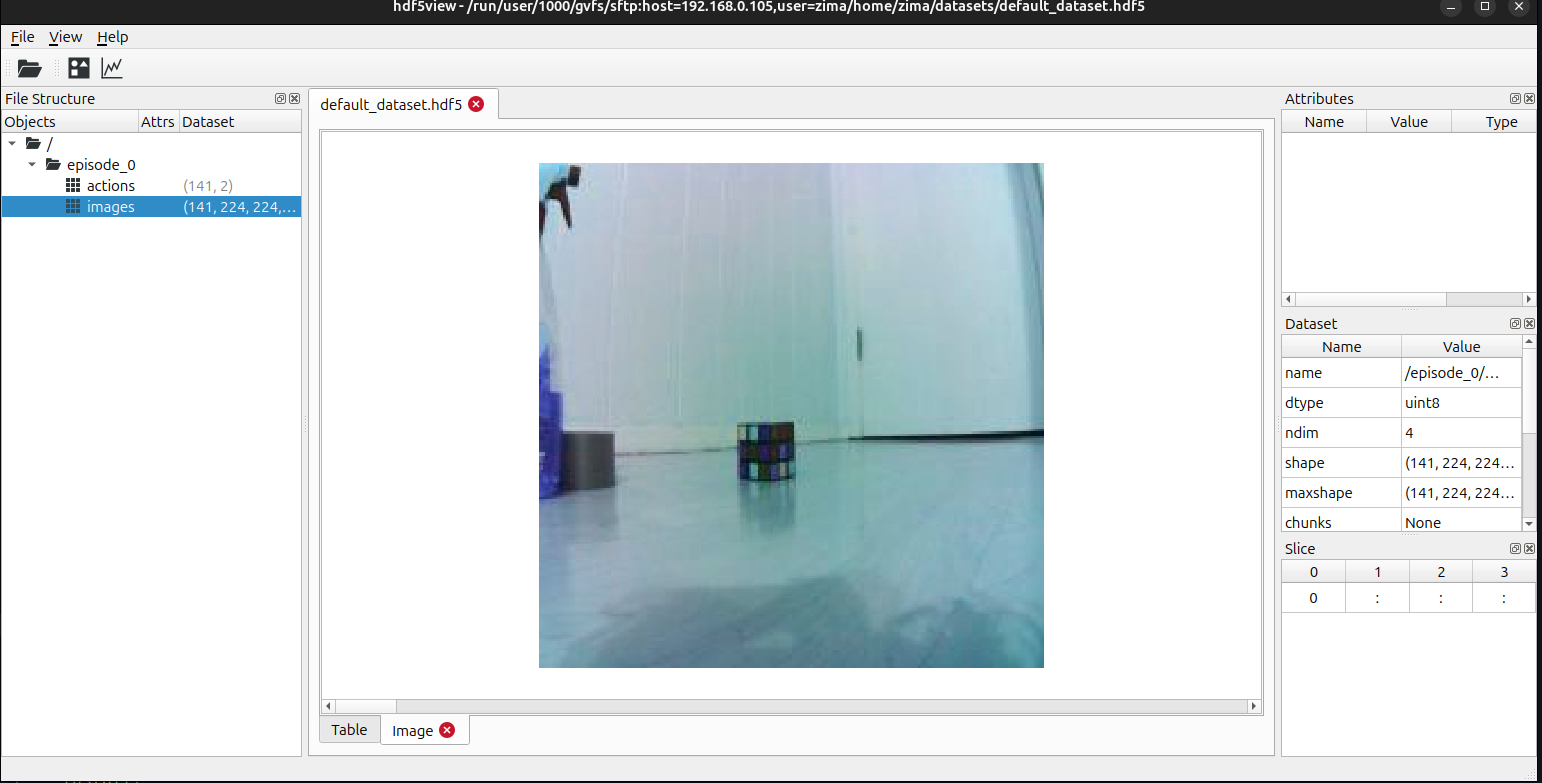
- real world episode data collection working
- 
What failed:
- sim data only model did not successfully complete the navigation task
- Due to random softmax sampling, the robot moved a little bit, but pretty much only by random chance
- appears that the camera input is too different from sim to work zero-shot
Key learning:
- Sim to real is not trivial (already knew that!)
Next session:
- Collect real world data and fine tune
- convert all datasets to be rgb by default
- convert dataset collection code in mujoco and ros2
- convert the rubiks cube navigation dataset to rgb
- Match sim camera to be more similar to real life?
- more fisheyed, make similar fov
- do some color shifting of the sim camera data
- maybe implement the "realisimifying" as dataset augmentation, not changes to the dataset collections
- maybe increase the contrast of the real camera data
Time spent: 3.5 hours
Nov 17 2025- MacOS compatibility
Goal: Get simulation, model inferencing, and training working on macbook
What I did:
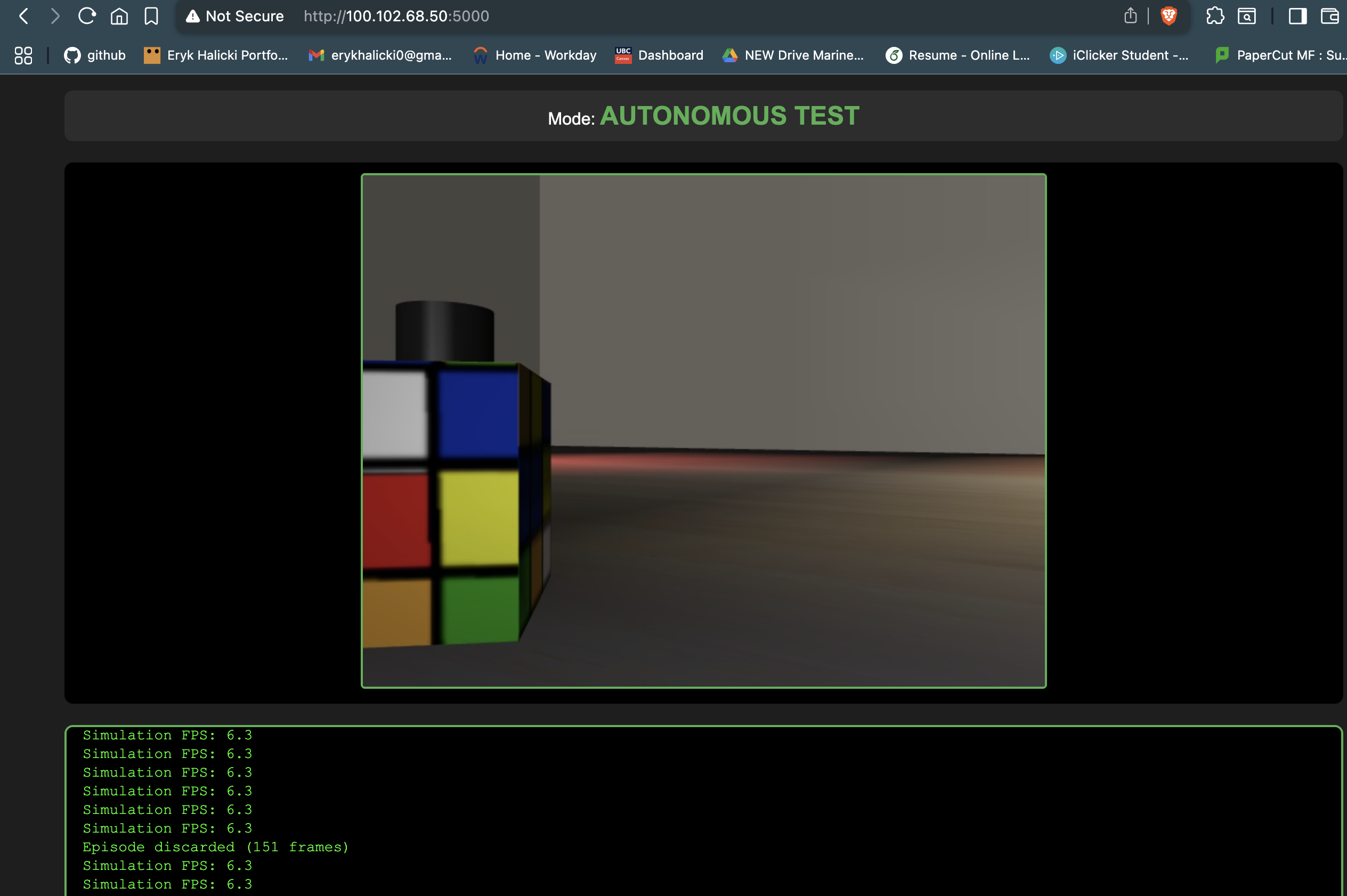
- Refactored mujoco teleoperation interface to use flask web server
- mainly to circumvent macos quirks, but also future proofing for headless setup
- Got headless mujoco setup working
- refactored training script for headless environments
- Added model training resumption from weight file
- Stressed over grad school applications (will I get in anywhere that does VLA work???)
- Collected 150 more episodes of training data by supervising autonomous operation
- Allowed model to run in simulation, discarded failed episodes, saved successful ones
- surprisingly did not noticeably improve task performance after retraining
What worked:
- Was able to successfully get data collection and model testing working on mac, both locally and headless connection to pc
- 
- Quality of life upgrades (cleaning up training script and adding training resumption) worked seamlessly
What failed:
- running mujoco locally on mac is inconvenient and not as well supported as linux
- tripling amount of collected episodes did not noticeably improve performance
Key learning:
- Macos and linux dont play as nicely together as i would have thought
- may need to start looking into docker when deploying on real cloud instances
Next session:
- begin sim 2 real testing and data collection
- write model inferencing code for ros2 / hardware interface
- inference on gpu, either write web server or use ros2 directly
- test pure sim policy on real hardware
- set up real world data collection pipeline (ros2 bag post-processing?)
- publish devlog on eryk.ca eventually
Time spent: 3 hour
Nov 16 2025 - evaluated model in more realistic sim environment
Goal: Create a more realistic sim environment (prepping for sim2real) and see if model can generalize
What I did:
- create a simulated bedroom environment in mujoco
- created simulated rubiks cubes (for navigation and manipulation task)
-
- tested if model works in new sim environment
- collected 75 episodes of training data on similar task (locate rubiks cube in scene)
- added model metadata to weight files to stop wasting time modifying params in simulation file
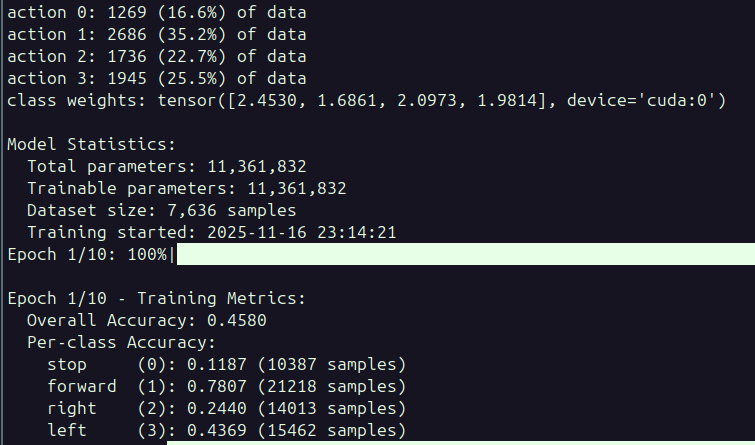
- trained model on new dataset with good results (~70-80% task completion rate)
- 
What worked:
- created a room scene fairly easily
- got randomized lighting working
- 
- 

What failed:
- original green cube task model was not able to generalize to new scene, although this makes sense since it was completely different from the original training data
Key learning:
- got more familiar with mujoco scene building
- when dataset variety is low, generalizability is low
Next session:
- begin sim 2 real testing and data collection
- write model inferencing code for ros2 / hardware interface
- inference on gpu, either write web server or use ros2 directly
- test pure sim policy on real hardware
- set up real world data collection pipeline (ros2 bag post-processing?)
- publish devlog on eryk.ca eventually
Time spent: 5 hours
Nov 15 2025 - EUREKA, task successfully completed!
Goal: figure out how to prevent regression to mean / mode collapse
What I did:
- watched sergey levine lecture on IL to get some background and inspiration
- discretized action space since it is tractable with 2dof (only 4 bins for current task)
- tried to fix data by removing idle franes
- tried to fix training weights using inverse frequency
- collected new, simpler dataset with reduced sampling rate and more balanced action distribution
- FIXED THE SIM EVALUATION PROBLEM!
- turned out to be a missing model.eval() ......
What worked:
- Balancing the dataset (trimming idle frames), discretizing action space, and ensuring the model was in eval mode got it to a functional state!
- Found good (>90% task success rate) hyperparameters to be:
- action chunk length: 4, action history: 4, actions discretized into 4 bins (forward, left, right, stop)
- Unfrozen resnet backbone with 1e-5 LR
- 3e-4 LR for action head
- training for ~10 epochs with 20000 samples
- Got more stable training with lower learning rates (the ones listed above)
- randomly sampling from the softmax of the output improves task completion rate noticably. It results in smoother motion and in some cases gives the model a kick in the right direction forcing it out of local minima
-
Demo of multiple successful task completions

What failed:
- Leaving model in training mode during sim evaluation caused BatchNorm layers to not work correctly, resulting in unexpected behavior
- model still has certain failure modes in simulation. Eg. approaching wrong color cube, looking at green cube then not approaching, etc
Key learning:
- Multimodal data is an issue for behaviour cloning on continuous action spaces in general (sergey levine lecture)
- expressive contiuous distributions solutions:
- mixture of gaussians: output X number of gaussian distributions from the model, then sample from them at inference time. (How do you optimize this / what is the training objective? Sergey said you take negative log of the MoG formula? Need to understand better)
- diffusion models: work by learning to remove noise from an input. This can be used in policy learning as well, by keeping state the same (image / observations) and noising the action to create training data, then training the model to denoise the action.
- High dimension discretization solutions:
-
- if you bin all dimensions you get exponentially many bins (eg. cannot bin every possible state of a 6dof arm tractably) Solution is to discretize each dimension individually
- Can be done using autoregressive discretization. We have a sequence model output each action dimension
- <img src="/assets/images/zima/Pasted image 20251115092110.png" alt="Pasted image 20251115092110" class="devlog-image">
- This works because we are only binning one dimension at a time (so if we have an action dimension $a_{t,0}$ from -1 to 1 we can put it in 10 bins for example) As such, the discretization problem becomes tractable. This also makes sense since dimension $a_{t,i+1}$ is predicted GIVEN $a_{t,i}$ , so we are only predicting "how likely is dimension i+1 to fall into this bin GIVEN that dimension i has value x".
- So at each "time step" of the sequence model, we output a probability distribution of each action dimension.
- Notice how at training time, we input the last action dimension (ground truth), but during inference, we would sample the distribution (possibly just picking the largest bin, or using random sampling) This is similar to how GPT / LLM style models work as well. its **auto-regressive**, since it uses its past output as input to the next time step
- <img src="/assets/images/zima/Pasted image 20251115093652.png" alt="Pasted image 20251115093652" class="devlog-image">
- This way, you train your entire policy while also discretizing the action space.
- Why not just discretize each dimension individually beforehand? (eg. bin each dimension into 10 bins and call it a day)?
- From what i understand right now, if we bin each action dimension and concatenate them, you end up with $\text{bin\_num} \times \text{action\_dimension}$ classes, which doesn't actually correspond to any specific action state, it would just be a flat list of possible values for each dimension, which doesnt make sense as an action distribution.
- You could instead train separate models to predict each dimension, and then bin the output there, but then you lose the dependencies between dimensions.
Next session:
- start doing sim to real work
- start with domain randomization
- then try to run model on hardware
- then collect data on hardware
Time spent: 11 hours
Nov 14 2025 - Model improvements
Goal: Iterate on model architecture and training recipe
What I did:
- Recorded new (cleaner?) dataset, with more consistent action completion strategy (turn clockwise ONLY while searching for cube)
- Added action history to input of model
- Implemented action chunk prediction
- changed loss function to L1 Loss
- mainly to avoid penalizing large errors as harshly, since that would discourage the model from outputting anything but the mean
What worked:
- nothing today
What failed:
- Even with larger dataset, and including action chunk prediction + action history input, the model regressed to the mean of the distribution
- tried a variety of hyperparamters, tried action history + action chunk prediction, and nothing worked
Key learning:
- 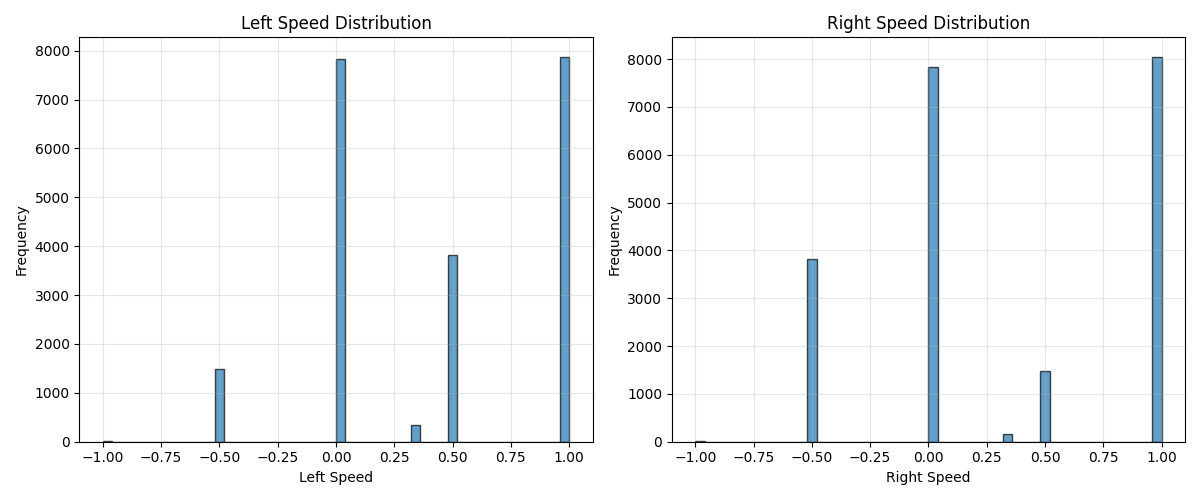
- action distribution is highly imbalanced, could benefit from weighting loss based on action frequency. I.E. more rare actions are weighted more heavily
- so if the model predicts incorrectly on a rare action, the loss will be very high
Next session:
- Reevaluate next steps
- discretize actions?
- increase weight of rare actions?
- undersample / oversample to even out data distribution?
Time spent: 6 hours
Nov 9 2025 pt.2 - Model evaluation and improvement
Goal: Test model in simulation, iterate and improve
What I did:
- Wrote a model adapter for the mujoco simulation to evaluate performance
- explored why model was under performing
- tested various training setups
- improved dataloading speed by caching transformed images instead of full episodes
What worked:
- Unfreezing resnet backbone significantly improved converged MSE (0.9 -> 0.6)
- Unfreezing backbone also improved prediction variance, indicating that the model started to learn more than just the mean of the action distribution
Unfrozen model backbone
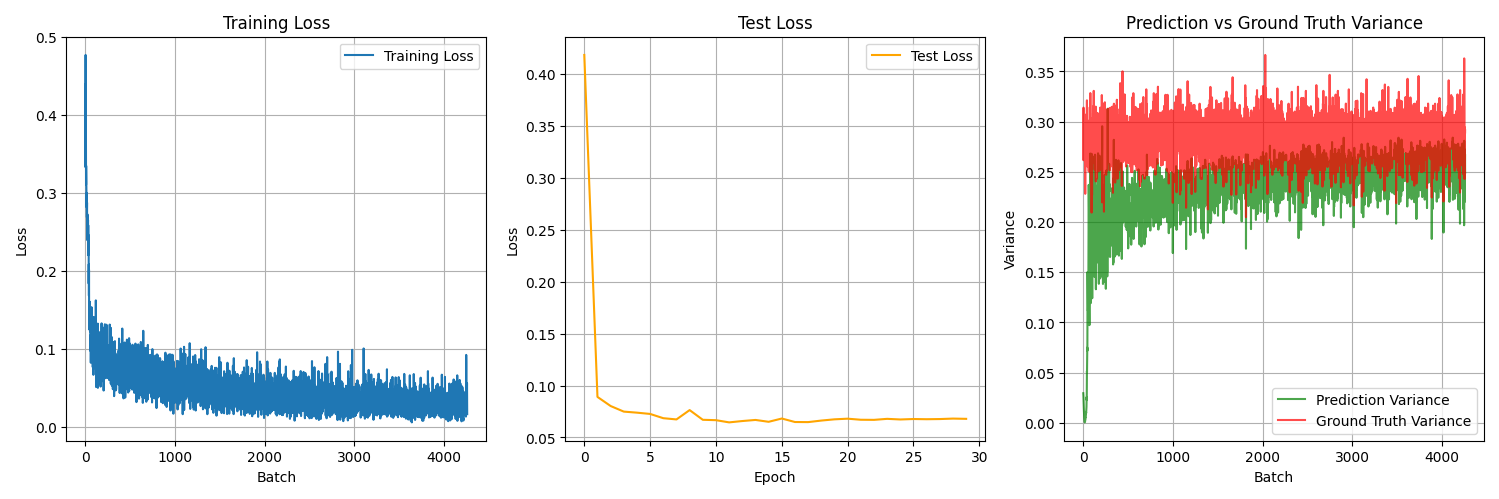
Frozen Model Backbone
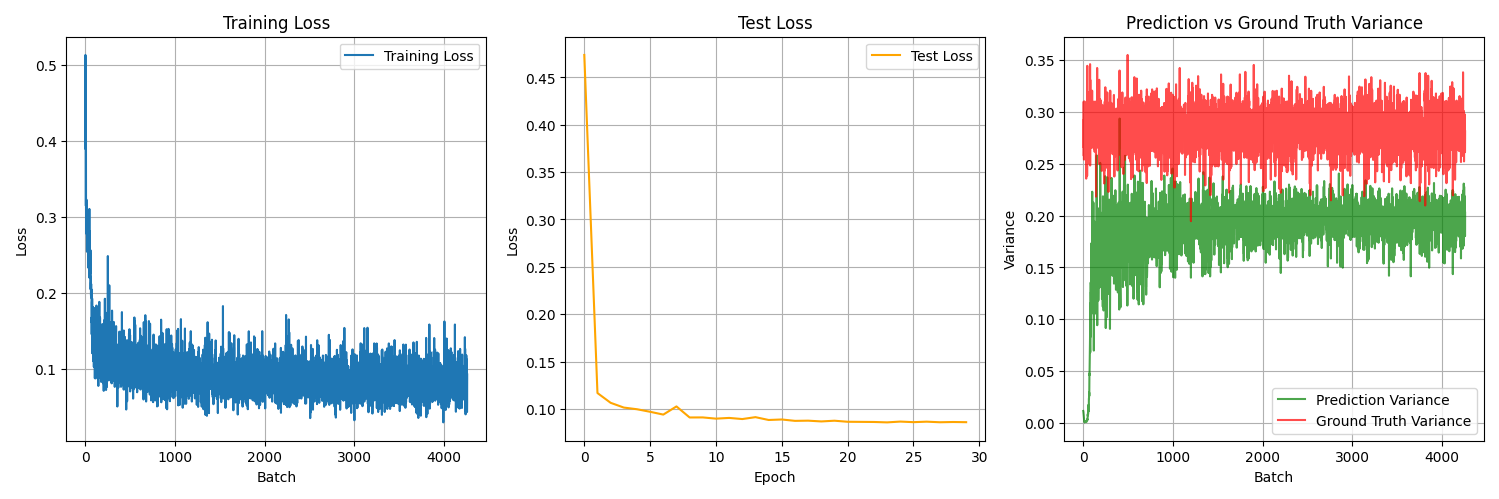
What failed:
- First model iteration didn't learn anything meaningful, it just drove in a straight line when put into simulation
- Second model iteration (unfrozen backbone) was able to learn a bit better, but still didnt accomplish task
- Running out of RAM. VRAM is still ok but will run our fairly fast if model size increases
Key learning:
- If model is unable to meaningfully learn from features, output variance will stay lower than data distribution variance (can be seen in above graphs)
- essentially the model learns to sit around the mean, learning P(X) instead of P(X|Y)
- Could this be specific to the MSE loss function?
- Starting to look like model cannot learn with no temporally correlated features
Next session:
- test new model architectures
- mainly try to change how the data is used (action chunk predictions, some kind temporal features, etc)
- test different loss functions
- Collect cleaner dataset? (only turn clockwise)
Time spent: 3 hours
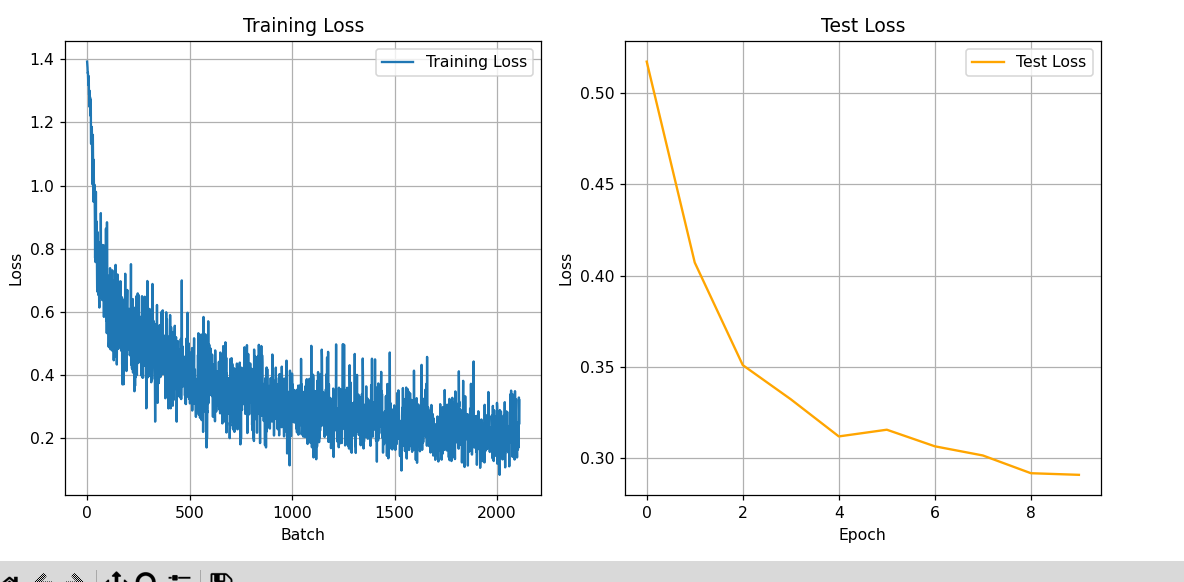
Nov 9 2025 - Dataset loading
Goal: One sentence
What I did:
- Got torch dataset and dataloader working with hdf5 data
- transformed data into resnet format
- Finished first iteration of model design
- Wrote training and testing loop
- Trained first model and visualized losses
What worked:

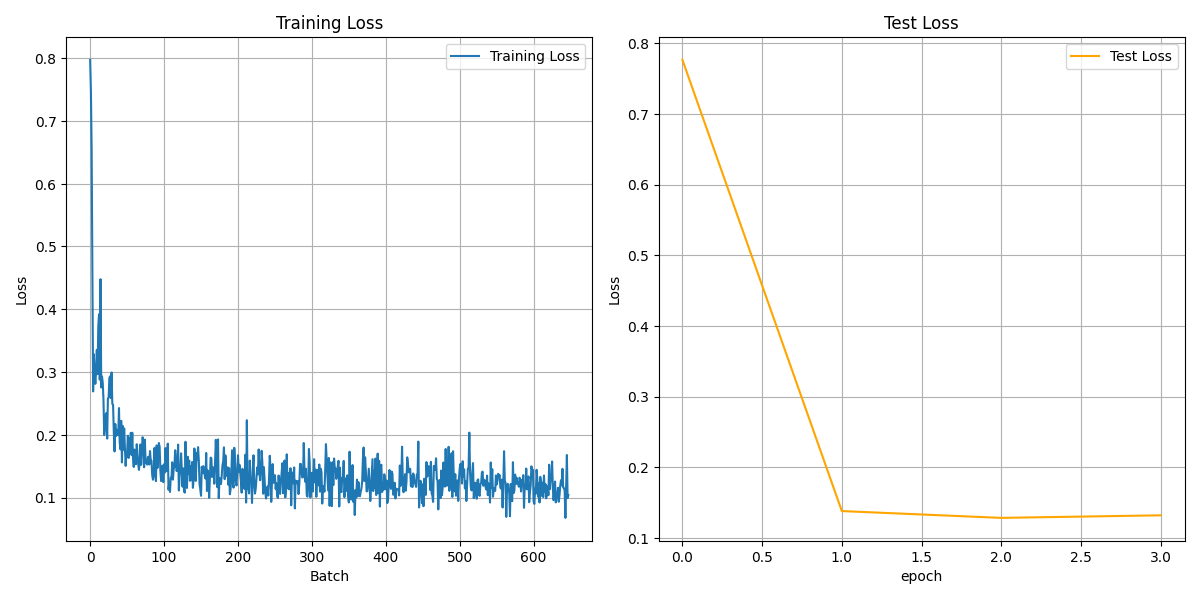
- Starting to feel familiar with python matrix manipulation
- Model appears to converge! Unsure how good performance will be on actual tasks
- model has 0 temproal context, so i predict that it ill be very jittery, especially when there are no green cubes in sight
What failed:
- Data loading is main bottleneck with training
- 95% of training cycle time is waiting for dataloader
- model stopped improving test and training loss after ~epoch 2
- maybe this is fine?
Key learning:
- Data loading can significantly slow down training
Next session:
- Test model in simulation
- need to make a new controller class that inferences model
Time spent: 5 hours
Nov 8 2025 - Building model and collecting data
Goal: Start building pytorch action model and training pipeline. Collect dataset
What I did:
- Collected 10 minutes of demonstrations (~70 demonstrations)
- Created the ActionResNet model (resnet18 as features extractor + 2 layer action head)
- Started writing dataset loading code + training loop
- learned more about pytorch
What worked:
- data collection pipeline works great
- using pretrained resnet weights is pretty intuitive
- creating action head is dead easy
- feeling more comfortable with pytorch syntax
- creating dataloader looking easy, should combine with the hdf5 class in sim folder
What failed:
- Very tired
- Not sure if this folder structure makes the most sense
- need to reorganize folders, maybe make a single folder for imitation learning instead of seperate ml and sim folders
Key learning:
- tanh saturates at extremes, not good to use if data is close to extremes often
- model.train and model.eval does NOT automatically set param.requires_grad = False, it just changes behaviour of dropout and batch normalization
- nn.Module.add_module can be used to make stuff accessible using model.children and model.apply
- dont use L2 norm on output, then we just end up with only direction! (makes sense since we would only outut unit vectors, but just something to keep in mind)
Next session:
- create torch dataloader / dataset for image action pairs (combine with hdf5 code?)
- test model output / forward run works correctly
- write training loop
- train and visualize validation loss to see if model is converging
- create controller that
Time spent: 2 hours
Nov 6 2025 -Mujoco setup
Goal: Set up a full teleloperated simulation in mujoco with data collection
What I did:
- created a wheeled / tank robot model in MJCF
- debugged weird physics
- added camera functionality to simulation
- added keyboard teleoperation for data collection
- added hdf5 dataset collection for image - action pairs
What worked:
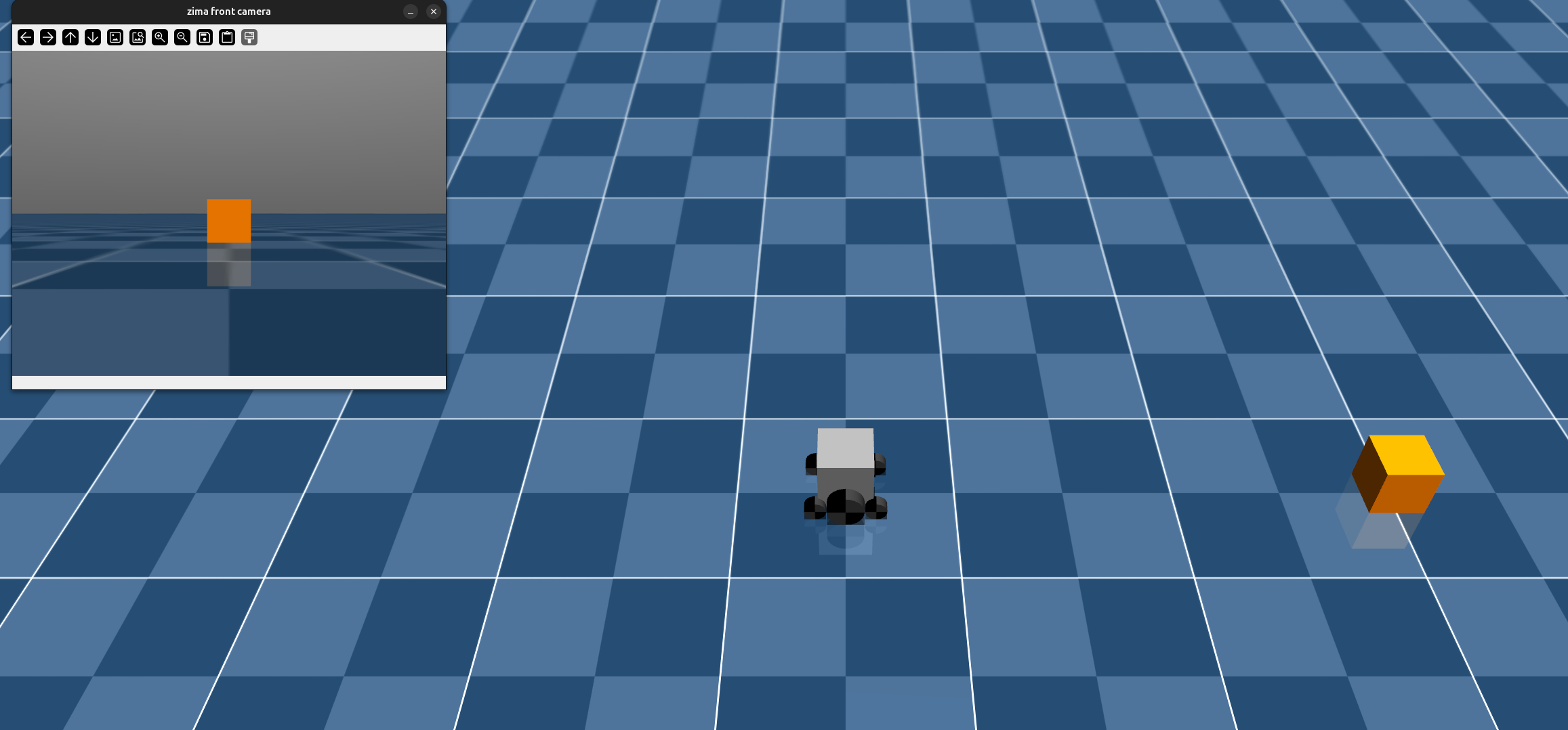
What failed:
- copying someone elses robot didnt work very well
- physics time steps were differing between my python code and the xml
- was this even an issue if it gets overridden?
Key learning:
- writing MJCF xml is tedious
- claude code is not that good at it
- mujoco is not so bad, easier to use than gazebo arguably
- hdf5 is a commonly used dataset format for robotics / scientific data
- h5py converts numpy arrays to hdf5 format
Next session:
- Collect 5 minutes of episodes (~30 episodes)
- task: search for and approach green cube (visual servoing)
- train a basic model to generate actions!
- resnet as fixed feature extractor
- train action head with 2-3 layers
- add CD to obsidian repo so zima devlog auto uploads to eryk.ca
Time spent: 4 hours
Nov 2 - Hardware improvements
Goal: Install cameras and clean up internals
What I did:
- Reorganized / cleaned up circuit board layout inside main enclosure
- Installed 2 cameras (1 wrist and 1 forward mounted)
- Wrote basic ros2 camera driver using opencv
What worked:
- Camera data streaming working!
- pcbs rearranged inside to make more room for main computer and battery
What failed:
- Internet bandwidth issues for camera streaming
- fixed using compression
- FOV of forward facing camera lower than expected, cannot see gripper in all positions
Key learning:
- uncompressed image data is larger than expected
Next session:
- add a basic scene (plane + cube) to Mujuco
- add a basic tracked robot (find online? use ai? differential drive)
- control basic tracked robot using keyboard
- update data.ctrl to control tracks
- eventually add zima stl files and get a proper simulation going
- capture camera data within simulation
Time spent: 2 hours
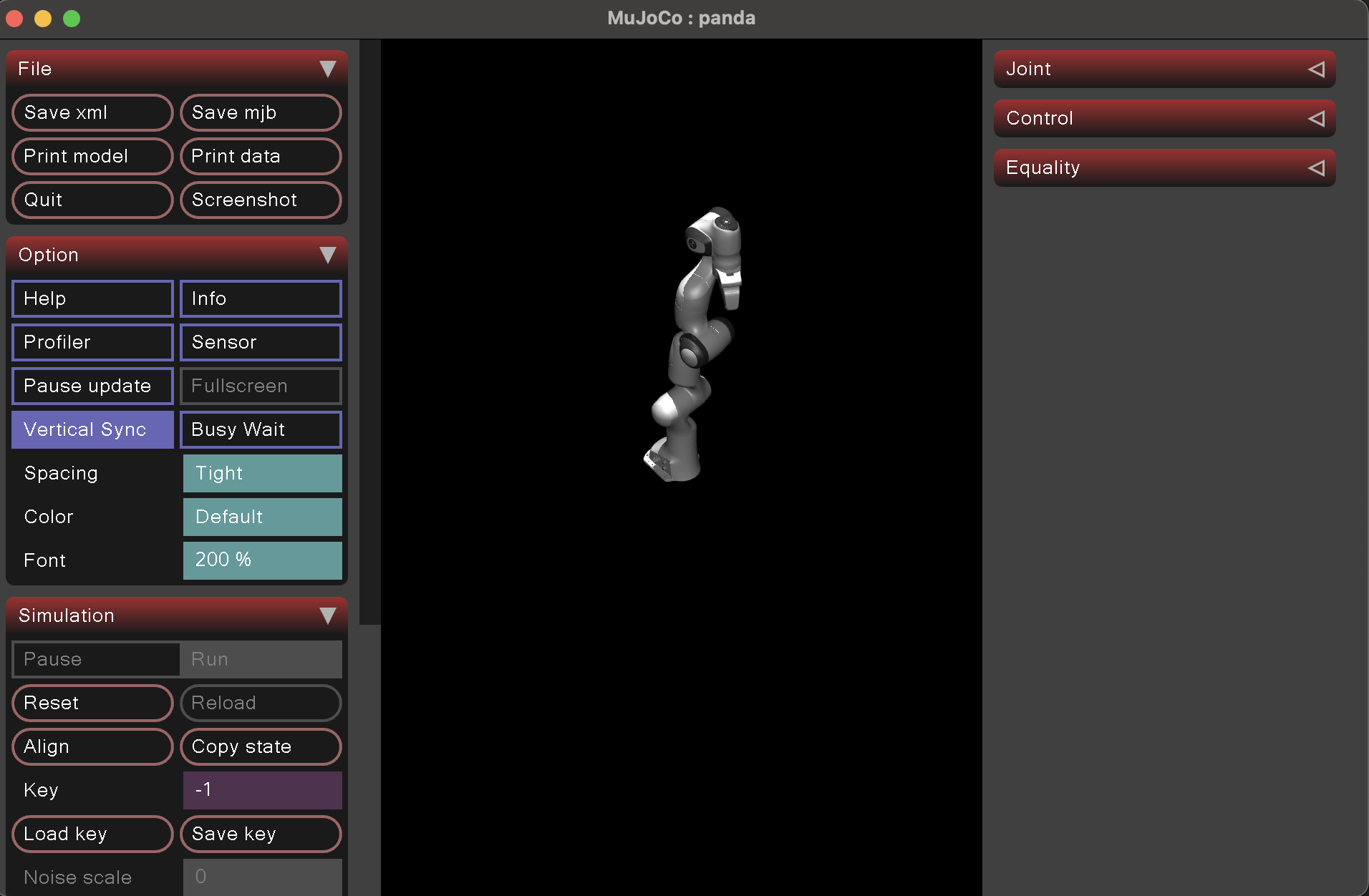
Oct 29 2025 - Sim tryouts and selection
Goal: implement a basic tracked robot in PyBullet
What I did:
- Read start of PyBullet quickstart quide
- Gave up on PyBullet because it was insanely slow despite being "lightweight"
- Made a Mujoco demo with claude code and basic examples from repo
- read some mujoco docs - https://mujoco.readthedocs.io/en/stable/python.html
- researched isaac sim min specs
What worked:
- got both Mujoco and pybullet running on my mac
- 
What failed:
- PyBullet speed was subpar (3fps rendering), and documentation was tragic (literally in a google doc)
- Mujoco was a little bit more overwhelming than i anticipated, but im catching on quick
Key learning:
- The documentation for these simulators is not the greatest
- PyBullet too slow + bad docs → switching to Mujoco
- Mujoco has steeper learning curve but better performance
- Mujoco uses data + model
- data contains the state of the sim, and we update it between time steps
- model contains scene and robot information, and defines how the simulator will update the data at each timestep
- Isaac sim is cool and probably the best option, but incredibly heavyweight (min spec rtx 4080 and 16gb vram)
Next session:
- add a basic scene (plane + cube) to Mujuco
- add a basic tracked robot (find online? use ai? differential drive)
- control basic tracked robot using keyboard
- update data.ctrl to control tracks
- eventually add zima stl files and get a proper simulation going
- capture camera data within simulation
Time spent: 2 hours
October 28 2025 - Running hardware again
Goal: Connect to on board computer remotely, control tracks and arm using ros2 commands
What I did:
- turned on the robot
- fixed networking issues
- manually published ros2 messages from zima_msgs to control arm and base
What worked:
- Everything still worked
- battery charged as expected without needing to unplug it
What failed:
- Arm inverse kinematics are buggy, but do work
- Lights inside the frame never turn off, may need to add a switch to prevent battery from draining
Key learning:
- N/A
Next session:
- Next hardware session, add camera and possibly switch
- Begin implementing PyBullet simulation of Zima
Time spent: 1 hours
Early October 2025 - brushing up on PyTorch basiscs
Goal: traing a basic CNN on MNIST dataset using pytorch
What I did:
- Following intoductory CNN MNIST tutorial
What worked:
- Model training success (98% accuracy and test set)
What failed:
- Nothing
Key learning:
- Got more familiar with PyTorch
Next session:
- N/A
Time spent: 3 hours
Jan - October 2025 - Laying Hardware Groundwork
Goal: Have a fully functional hardware prototype
What I did:
- CAD modelled and 3D printed frame
- Hacked together tracks + motor encoders for tracked base
- CAD modelled and printed 5DOF arm and gripper
- Implemented all servo and power distribution electronics
What worked:
- Robot works!
- Can roll around, and track position using encoders
- Can manipulate arm using inverse kinematic server (buggy)

What failed:
- electronics are a fragile mess
- didnt get around to printing a head for the camera
- arm is weaker than expected, gripper design needs to be updated
Key learning:
- Hardware is very difficult
- Inverse kinematic libraries are few and far between and not well documented
Next session (future direction of project):
- Implement intelligent control (ResNet→action network)
- Add camera to arm
- Set up sim environment for policy training
Time spent: 100 hours